Esta es la sección de documentación del proyecto Kore Ledger. En este lugar encontrarás la descripción de la tecnología y sus posibles casos de uso, los antecedentes que nos llevaron a abordar su desarrollo, información técnica detallada sobre los diferentes componentes de la arquitectura y diferentes tutoriales que te ayudarán a implementar diferentes soluciones de trazabilidad.
Versión imprimible multipagina. Haga click aquí para imprimir.
Documentación
- 1: Descripción general
- 1.1: DLT
- 1.2: Trazabilidad
- 1.3: Propuesta de valor
- 1.4: Casos de uso
- 1.5: Bajo el capó
- 2: Empezando
- 2.1: Conceptos
- 2.1.1: Gobernanza
- 2.1.2: Sujeto
- 2.1.3: Roles
- 2.1.4: Esquema
- 2.1.5: Eventos
- 2.1.6: Identidad
- 2.1.7: Nodos
- 2.1.8: Contratos
- 2.2: Conceptos avanzados
- 2.2.1: Proceso de aprobación del evento
- 2.2.2: Proceso de evaluación de eventos
- 2.2.3: Proceso de validación de eventos
- 2.3: Glosario
- 3: Aprende
- 3.1: Gobernanza
- 3.2: Contratos
- 3.2.1: Contratos en Kore
- 3.2.2: Programación de contratos
- 3.3: Aprende JSON Schema
- 3.4: Kore Base
- 3.4.1: Arquitectura
- 3.4.2: FFI
- 3.5: Kore Node
- 3.5.1: Qué es
- 3.5.2: Configuración
- 3.6: Kore Clients
- 3.6.1: Kore HTTP
- 3.6.2: Kore Modbus
- 3.7: Herramientas
- 4: Políticas
- 4.1: Aviso legal
- 4.2: Privacidad
- 4.3: Igualdad y diversidad
1 - Descripción general
Descripción general de la tecnología Kore Ledger y sus aplicaciones.
Kore Ledger es una tecnología de contabilidad distribuida (DLT) diseñada y construida específicamente para la trazabilidad de la procedencia y el ciclo de vida de los activos y procesos. Se complementa con un marco y modelo de gobernanza que facilita la interacción y cooperación entre múltiples actores en escenarios de alta complejidad (economía circular, producción de energía, ciclo integral del agua, producción agroalimentaria, etc.)
1.1 - DLT
Concepto de Tecnología de Contabilidad Distribuida (DLT por sus siglas en inglés).
¿Qué es DLT?
DLT es un acrónimo de Distributed Ledger Technology, que en español se traduce como Tecnología de Contabilidad Distribuida. Este concepto se refiere a una base de datos distribuida, que se replica y sincroniza en múltiples nodos de la red y es accesible para varias partes. Esta tecnología nos permite almacenar copias de registros idénticos en diferentes computadoras, lo que facilita que varios participantes los vean y actualicen. A diferencia de las bases de datos distribuidas tradicionales, funciona como un libro de contabilidad: sólo se pueden agregar registros nuevos y los antiguos no se pueden eliminar ni modificar. Esta idea ha llamado la atención en la última década porque una de sus variantes, la tecnología blockchain, sustenta la mayoría de las criptomonedas.

(Izquierda) Tecnología de contablidad centralizada. (Derecha) Tecnología de contabilidad distribuida.
Figural 1: Registro centralizado vs. Registro distribuido.
1.2 - Trazabilidad
¿Qué es la trazabilidad y por qué es tan importante?
La norma UNE 66.901-92 define la trazabilidad como
“la capacidad para reconstruir el historial de la utilización o la localización de un artículo o producto mediante una identificación registrada”
- La trazabilidad permite rastrear los productos y bienes a medida que se mueven a lo largo de la cadena de valor, obteniendo información fidedigna sobre la procedencia de los insumos, las prácticas de abastecimiento de proveedores y los procesos de transformación.
- Ofrece a las empresas la capacidad de identificar oportunidades estratégicas en la optimización de las cadenas de valor, innovar mucho más rápido, minimizar el impacto de las interrupciones de suministro internas y externas, y ofrecer la certificación de procesos y productos más sostenibles.
- La digitalización de la trazabilidad es el punto de partida para nuevas cadenas de valor circulares y transparentes que reduzcan el uso de materiales, y que reutilicen o reciclen productos, reduciendo los costos y creando menos residuos.
1.3 - Propuesta de valor
La propuesta de valor de Kore Ledger.
Kore Ledger es la combinación de las palabras “verde” en el idioma africano “hausa”, y “libro contable” en inglés. Es una iniciativa empresarial para proporcionar la tecnología y el marco de trabajo necesarios para la trazabilidad de la procedencia y ciclo de vida de activos y procesos.
El factor diferencial es que se hará de forma descentralizada, segura e inmune a la manipulación, garantizando además la privacidad de los datos y la sostenibilidad de las soluciones. Este planteamiento proporciona una solución integral, económica, de fácil implantación y no invasiva con la digitalización existente en nuestros clientes.
Por otra parte, la tecnología de Kore Ledger ofrece la capacidad de enlazar la información de trazabilidad de diferentes sujetos y a diferentes niveles de su ciclo de vida, lo que la convierte en la solución ideal en el ámbito de economía circular, producción de energía sostenible, ciclo integral del agua, huella de carbono, trazabilidad agroalimentaria, seguridad industrial, etc.
Kore Ledger ofrece la mejor solución de infraestructura tecnológica para la digitalización de la trazabilidad de activos y procesos. Basada en una tecnología de registro distribuido segura e inmune a la manipulación, proporciona unos niveles de escalabilidad muy superiores a otras soluciones equivalentes, y de una forma mucho más sostenible.
- Proporcionando una línea de producción de soluciones que reduce de forma drástica el tiempo y coste de lanzamiento de soluciones al mercado.
- Sustentada en un marco de trabajo que facilita la formalización de modelos de trazabilidad que satisfagan los requisitos específicos de cada cliente, ofreciendo un retorno inmediato
Con una tecnología diseñada para una escalabilidad ilimitada, capacidad para ser ejecutada en dispositivos con recursos limitados (móviles, IoT, …), soporte a la criptografía más avanzada y la máxima eficiencia energética.
¿Qué nos diferencia de una blockchain?
| Aspecto | Blockchain | Kore Ledger |
| Función |
|
|
| Coste |
|
|
| Eficiencia |
|
|
1.4 - Casos de uso
Diferentes casos de uso de trazabilidad con Kore Ledger.
Kore ha sido diseñado teniendo en cuenta los casos de uso de trazabilidad. Se considera que en estos casos de uso la gran mayoría de eventos son unilaterales, lo que permite aprovechar las características diferenciadoras de Kore, como el modelo de propiedad única del libro mayor. Algunos casos de uso de la tecnología Kore se presentarán como ejemplos para facilitar la comprensión.
Procesos
Cualquier proceso que requiera trazabilidad con altos niveles de seguridad y confianza puede ser un caso de uso adecuado para rastrear a través de nodos Kore, por ejemplo, el ciclo del agua. Este proceso describe cómo el flujo de agua parte de un punto A y pasa por una serie de otros puntos hasta finalmente regresar al punto de origen, simulando un camino circular. En su recorrido, el flujo de agua pasa por diversas entidades y procesos que hacen que su volumen disminuya. Simultáneamente, en algunos de estos puntos es posible analizar el estado de ese flujo mediante sensores u otros sistemas que permitan obtener y generar información adicional del propio flujo.
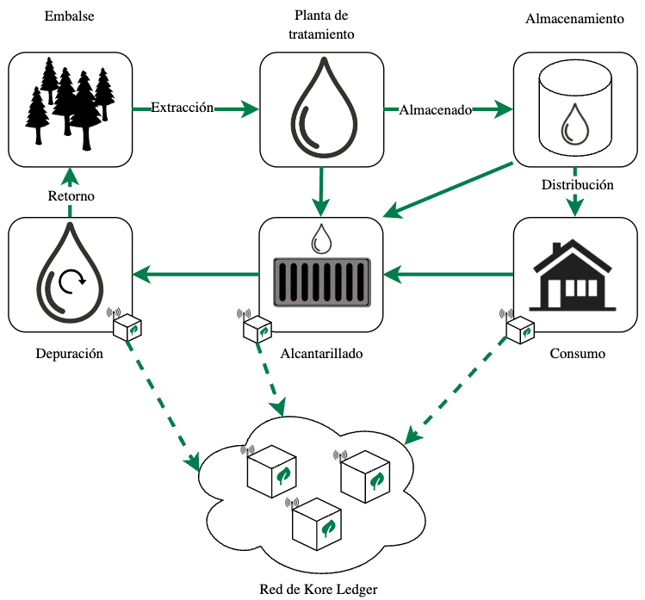
Figura 1: Ciclo del agua con Kore Ledger.
Iot
IoT se define como Internet de las cosas. El Internet de las cosas describe objetos físicos (o grupos de dichos objetos) con sensores, capacidad de procesamiento, software y otras tecnologías que se conectan e intercambian datos con otros dispositivos y sistemas a través de Internet u otras redes de comunicaciones. Por ejemplo, el concepto de ciudad inteligente ha ido ganando impulso últimamente.
Hoy en día, los beneficios de una ciudad no sólo se limitan a la infraestructura física, los servicios y el apoyo institucional, sino también a la disponibilidad y calidad de los canales de comunicación, y a la transmisión y explotación del conocimiento a partir de estos canales para mejorar y dotar eficientemente de recursos a las infraestructuras sociales. .
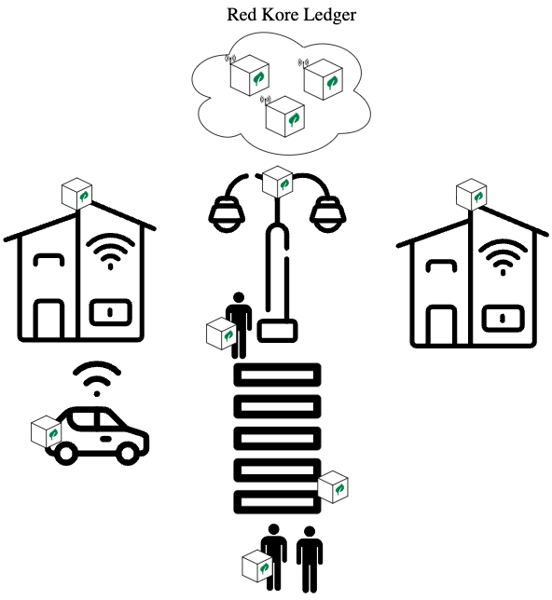
Figura 2: Ciudad inteligente conectada a la red Kore Ledger.
Uno de los procesos más interesantes dentro de una ciudad inteligente, tanto por sus implicaciones para la salud pública como por su carácter económico, es la gestión de residuos. El primer paso es recoger la basura proporcionada por los ciudadanos en contenedores que cuentan con sensores u otros sistemas que determinan el peso del contenedor y su nivel de llenado. Una vez activado el sensor al valor marcado por la empresa, el camión de la basura recoge el contenedor para llevarlo a la fábrica de reciclaje, donde se encargan de separar estos elementos y realizar los procesos pertinentes para su reciclaje. Finalmente, cuando finaliza el proceso, estos materiales se vuelven a poner a la venta para que puedan ser utilizados nuevamente y se repite el proceso explicado anteriormente.
Trazabilidad de la Carne de Res
La carne de res es un producto común en los supermercados y su trazabilidad es crucial para garantizar su calidad, seguridad y origen. Con Kore, se puede implementar un sistema de trazabilidad para la carne de res desde el campo hasta la mesa, siguiendo estos pasos:
- Cría y Alimentación del Ganado: El sistema comienza con la cría y alimentación del ganado en granjas. Kore puede registrar información sobre la procedencia del ganado, su genética, dieta, condiciones de cría y salud. Los datos pueden incluir el tipo de alimentación (orgánica, convencional), el uso de medicamentos y otros detalles importantes.
- Sacrificio y Procesamiento: Cuando el ganado es sacrificado, Kore registra los datos del proceso, incluidos los controles de calidad, la fecha y el lugar del sacrificio. Durante el procesamiento, se puede hacer un seguimiento de los cortes de carne y los subproductos, garantizando la trazabilidad de cada pieza.
- Transporte y Almacenamiento: Kore permite el seguimiento de la carne durante el transporte desde la planta de procesamiento hasta los centros de distribución y tiendas. Se pueden monitorear las condiciones de transporte, como la temperatura, para asegurarse de que la carne se mantenga en condiciones óptimas.
- Distribución a Supermercados: Una vez que la carne llega a los supermercados, Kore puede registrar datos sobre su almacenamiento, rotación y exposición en las estanterías. Los minoristas pueden acceder a información detallada sobre el origen de la carne y sus características, lo que les permite tomar decisiones informadas sobre la venta.
- Venta al Consumidor Final: Los consumidores pueden acceder a la información de trazabilidad mediante códigos QR o etiquetas en el empaque de la carne. Esto les permite conocer el origen de la carne, su historial de calidad y cualquier otra información relevante.
Este nivel de trazabilidad garantiza que los consumidores reciban carne de res de alta calidad y que se cumplan los estándares de seguridad alimentaria. Además, ayuda a prevenir fraudes y a identificar rápidamente problemas en caso de brotes de enfermedades transmitidas por alimentos.
1.5 - Bajo el capó
Tecnologías empleadas por Kore Ledger
Rust
Rust es un lenguaje de programación desarrollado inicialmente por Graydon Hoare en 2006 mientras trabajaba en Mozilla, empresa que luego apoyaría oficialmente el proyecto en 2009, logrando así su primera versión estable en 2014. Desde entonces, la popularidad y adopción del lenguaje ha ido en aumento. por sus características, recibiendo el apoyo de importantes empresas de la industria como Microsoft, Meta, Amazon y Linux Foundation entre otras.
Rust es el lenguaje principal de la tecnología Kore. Su principal característica es la construcción de código seguro, implementa una serie de funcionalidades cuyo propósito es garantizar la seguridad de la memoria, además de agregar abstracciones de costo cero que facilitan el uso del lenguaje sin requerir sintaxis complejas. Rust es capaz de proporcionar estas ventajas sin afectar negativamente al rendimiento del sistema, tanto desde el punto de vista de la velocidad de un proceso en ejecución, como de su consumo energético. En ambas características mantiene rendimiento igual o similar a C y C++.
Se eligió Rust como tecnología precisamente por estas características. Desde Kore ledger damos gran importancia a la seguridad del software desarrollado y a su consumo energético y Rust fue precisamente el lenguaje que cubrió nuestras necesidades. Además, al ser un lenguaje moderno, incluye ciertas utilidades y/o características que nos permitirían avanzar más rápidamente en el desarrollo de la tecnología.
LibP2P
Libp2p es una “pila de tecnologías” centrada en la creación de aplicaciones peer-to-peer. Así, LibP2P permite que su aplicación construya nodos capaces de interpretar una serie de protocolos seleccionables, que pueden ser tanto de transmisión de mensajes como de cifrado, entre otros. Libp2p va un paso más allá ofreciendo las herramientas necesarias para construir cualquier protocolo desde 0 o incluso crear wrappers de otros existentes o simplemente implementar una nueva capa de alto nivel para un protocolo manteniendo su funcionamiento de bajo nivel. LibP2P también gestiona la capa de transporte del propio nodo y ofrece soluciones a problemas conocidos como “NAT Traversal”.
LibP2P también pone especial énfasis en la modularidad, de tal forma que todos y cada uno de los elementos anteriormente mencionados están aislados entre sí, pueden modificarse sin afectarse entre sí y pueden combinarse como se desee, manteniendo el principio de responsabilidad única y permitiendo reutilización de código. Una vez que se desarrolla un protocolo para LibP2P, se puede utilizar en cualquier aplicación independientemente de cuán diferentes sean entre sí. Este nivel de modularidad permite utilizar incluso diferentes protocolos dependiendo del medio a utilizar.
Kore eligió LibP2P debido a su enfoque innovador para la creación de aplicaciones P2P a través de sus herramientas y utilidades que facilitan enormemente el desarrollo. También influyó el hecho de que es una tecnología con trayectoria en el sector Web3, ya que originalmente formaba parte de IPFS y ha sido utilizada en Polkadot y Substrate así como Ethereum 2.0.
Tokio
Tokio es una biblioteca para Rust destinada a facilitar la creación de asincrónico y aplicacionesconcurrentes. Proporciona los elementos necesarios para la creación de un entorno de ejecución para la gestión de tareas, interpretados internamente como “hilos verdes” (que Rust no soporta de forma nativa). Así como canales de comunicación entre ellos. También es bastante fácil de usar gracias a su sintaxis centrada en “async/await” y tiene una alta escalabilidad gracias al reducido coste de creación y eliminación de tareas.
Por las características mencionadas anteriormente y centrándose en la concurrencia y la escalabilidad, Tokio es una biblioteca adecuada a las necesidades que quieras cubrir con la tecnología Kore.
2 - Empezando
¿Qué necesita saber un usuario para beneficiarse de la tecnología?
2.1 - Conceptos
Definiciones de conceptos clave en Kore Ledger.
2.1.1 - Gobernanza
Descripción de la gobernanza.
La gobernanza es el conjunto de definiciones y reglas que establecen cómo los diferentes nodos participantes en una red se relacionan con los sujetos de la trazabilidad e interaccionan entre si. Los componentes de las gobernanza son:
- Los nodos participantes.
- El esquema de los atributos de los sujetos.
- El contrato para aplicar los eventos que modifican el estado del sujeto.
- Los permisos de cada participante para participar en la red.
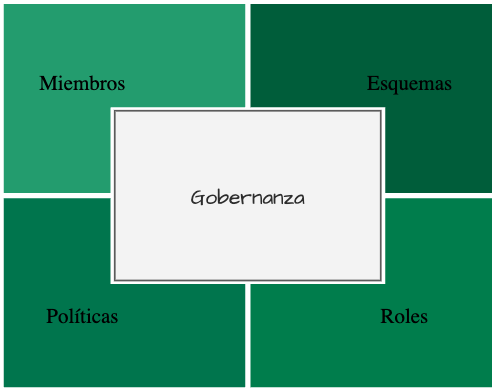
Figure 1: Componentes de la gobernanza.
Miembros
Estas son las personas, entidades u organizaciones que participan en la gobernanza y por tanto pueden ser parte de los casos de uso que se soportan. Cada miembro declara un identificador único que representa el material criptográfico con el que operará en la red, su identidad .
Esquemas
Los esquemas son las estructuras de datos que modelan la información almacenada en los sujetos. Dentro de una gobernanza, se pueden definir diferentes esquemas para admitir diferentes casos de uso. Cuando se crea un sujeto, define a qué gobierno está asociado y qué esquema utilizará. Además, cada esquema tiene asociado un contrato inteligente que permitirá modificar el estado de los sujetos.
Roles
Los roles representan grupos de participantes con algún tipo de interés común en un conjunto de sujetos. Los roles nos permiten asignar permisos sobre estos grupos de sujetos más fácilmente que si tuviéramos que asignarlos individualmente a cada miembro del gobierno.
Políticas
Las políticas definen las condiciones específicas bajo las cuales se afecta el ciclo de vida de un evento, como el número de firmas necesarias para llevar a cabo los procesos de evaluación, aprobación y validación. A esto se le llama quórum. La configuración de gobernanza permite la definición de [distintos tipos de quórum] , más o menos restrictivos, dependiendo de la necesidad del caso de uso.
ATENCIÓN
Como sabemos, el propietario de un sujeto es el único que puede actuar sobre él , y por tanto tiene absoluta libertad para modificarlo. La gobernanza no puede impedir que los propietarios maliciosos intenten realizar acciones prohibidas, pero sí define las condiciones bajo las cuales el resto de participantes ignoran o penalizan estos comportamientos maliciosos.La gobernanza como sujeto
La gobernanza es un sujeto de trazabilidad, dado que puede evolucionar y adaptarse a las necesidades de negocio, y por tanto su ciclo de vida también esta determinado por una gobernanza, lo que dota a nuestra infraestructura de transparencia y confianza para todos los participantes.
Jerarquía de relaciones
La gobernanza define las reglas a seguir en un caso de uso. Sin embargo, el titular de un nodo no está limitado a participar en un único caso de uso. Combine esto con la estructura de gobernanza y obtendrá la siguiente jerarquía de relaciones:
- Una gobernanza:
- definir uno o varios: miembros, políticas, esquemas y roles.
- admite uno o varios casos de uso.
- Un participante (persona, entidad u organización):
- tiene una identidad , y la identidad actúa como miembro de una gobernanza.
- ejecutar un nodo que almacena muchos sujetos.
- está involucrado en uno o varios casos de uso.
- Un sujeto:
- depende de una gobernanza.
- está modelado por un esquema.
- tiene espacios de nombres.
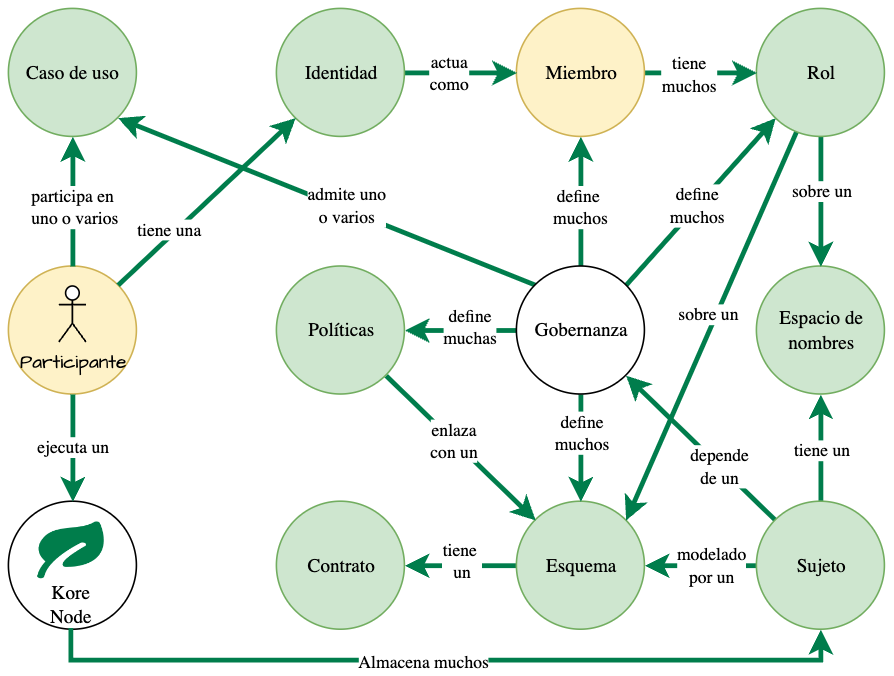
Figure 2: Jerarquía de relaciones .
2.1.2 - Sujeto
Descripción del sujeto.
En lugar de tener un único libro de contabilidad compartido por todos los participantes, la información se estructura sujeto por sujeto. Los sujetos son entidades lógicas que representan un activo o proceso dentro de una red
Cada sujeto cumple con lo siguiente:
- Contiene un único microledger.
- Tiene un estado modelado por un esquema.
- Tiene un solo dueño
- Depende de una gobernanza.
Microledger
Cada sujeto contiene internamente un libro de contabilidad en el que se registran los eventos que afectan únicamente a ese sujeto, el microledger. Este microledger es un conjunto de eventos encadenados mediante mecanismos criptográficos. Es similar a una blockchain en que los diferentes elementos de la cadena se relacionan incluyendo la huella criptográfica del elemento inmediatamente anterior, pero, a diferencia de las blockchains en las que cada bloque puede incluir un conjunto de transacciones, posiblemente de diferentes cuentas, en el microledger. cada elemento representa un único evento del propio sujeto.
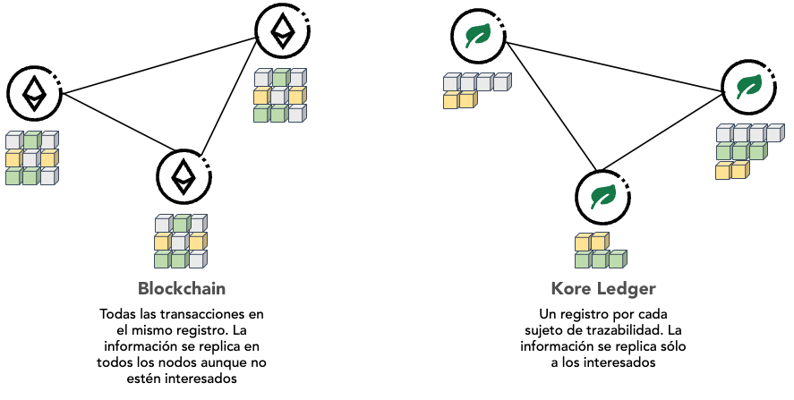
Figure 1: Registro de eventos en Blockchain y Kore Ledger.
Estado del Sujeto
El estado es la representación de la información almacenada por un sujeto en un instante determinado, normalmente el momento actual. El estado se obtiene aplicando, uno tras otro, los diferentes eventos del microledger sobre el estado inicial del sujeto definido en su evento-génesis.

INFORMACIÓN
La estructura del estado debe corresponder a un esquema válido. Para obtener más información sobre los esquemas, visite la página Esquemas.ATENCIÓN
A diferencia de otras DLT, Kore no tiene tablas de datos. La información se almacena en una sola entidad, el estado sujeto. Esta entidad debe representar únicamente el estado final de nuestro sujeto, mientras que los detalles de los diferentes eventos se almacenarán en el microledger.Modelo de propiedad
Cualquier sujeto tiene un único propietario, siendo este el único participante de la red que puede realizar modificaciones efectivas sobre el sujeto, es decir, agregar eventos en el microledger. Sin embargo, otros participantes, los emisores, pueden generar solicitudes de eventos. Estas solicitudes de eventos son firmadas por el emisor y enviadas al propietario del sujeto.
Pertenecer a una gobernanza
Un sujeto siempre existe dentro de un caso de uso. La gobernanza es la definición de las reglas por las que se rige el caso de uso. Qué tipos de sujetos se pueden crear o quién puede crearlos son algunas de las reglas que se definen en la gobernanza. Aunque un sujeto sólo puede pertenecer a una gobernanza, un nodo puede gestionar sujetos de diferente gobernanza, de modo que un mismo nodo pueda participar simultáneamente en diferentes casos de uso.
Espacio de nombres
Cuando se crea un sujeto, se le asocia cierta información, como la gobernanza, el esquema y un espacio de nombres. El espacio de nombres está asociado con el caso de uso y la gobernanza, ya que es el mecanismo mediante el cual se pueden segmentar las partes interesadas. En el mismo caso de uso, no todos los participantes pueden estar interesados en todos los sujetos, sino sólo en un subconjunto de ellos.
Identificador del sujeto y claves
A cada sujeto, en el momento de su creación, se le asigna un par de claves criptográficas con las que firmar los eventos de su microledger. A partir de la clave pública y otros metadatos se genera su Identificador de Asunto (subjectId) , que lo representa de forma única en la red.
2.1.3 - Roles
Descripción de los roles.
Cada participante de la red interactúa con ella en función de diferentes intereses. Estos intereses están representados en Kore como roles
Propietario
Posee el sujeto de trazabilidad y es el nodo responsable de registrar los eventos. Tienen control total sobre el sujeto porque posee el material criptográfico con permisos para modificarlo.
INFORMACIÓN
La propiedad del sujeto puede obtenerse creándola o recibiéndola del propietario anterior.Emisor
Aplicación autorizada a emitir peticiones de eventos, aunque no sea un nodo de la red. Todo lo que necesita para participar en la red es un par de claves criptográficas que permita firmar los eventos, además de tener los permisos necesarios en la gobernanza.
Evaluador
Los evaluadores asumen un papel crucial dentro del marco de gobernanza, siendo responsables de llevar a cabo el proceso de evaluación. Este proceso realiza la ejecución de un contrato, que generalmente resulta en un cambio en el estado del sujeto.
Aprobador
Para que ciertas solicitudes de eventos obtengan aprobación y se agreguen al microledger de un sujeto, es necesaria una serie de firmas. La adquisición de estas firmas depende del resultado de la evaluación. Durante la evaluación de un contrato, se toma una decisión sobre la necesidad de aprobación, que puede verse influenciada por las funciones del emisor solicitante.
Validador
Nodo que valida el orden de los eventos para garantizar la inmunidad a la manipulación. Esto lo consigue no firmando eventos con el mismo ID del sujeto y número de secuencia.
Testigo
Nodos interesados en mantener una copia del registro, aportando también resiliencia.
2.1.4 - Esquema
Descripción del esquema.
El esquema es la estructura del estado contenido en un sujeto.
Los esquemas se definen dentro de una gobernanza y, por tanto, se distribuyen junto con ella. Diferentes gobernanzas pueden definir esquemas equivalentes, sin embargo, para todos los efectos, dado que pertenecen a diferentes gobernanzas, se consideran esquemas diferentes.
Los esquemas se componen de 2 elementos:
- Un identificador único. Cada esquemas tiene un identificador que permite referenciarlo dentro de la gobernanzas en la que está definido. Se pueden definir diferentes esquemas dentro de una misma gobernanzas. Además, siempre que tengan identificadores diferentes, podrás crear esquemas con el mismo contenido.
- Un contenido. Es la estructura de datos utilizada para validar el estado de los sujetos.
{
"id": {"type":"string"},
"content": {"type": "object"}
}
INFO
Si desea aprender cómo definir un esquema JSON, visite el siguiente enlace.2.1.5 - Eventos
Eventos dentro de la red Kore Ledger.
Los eventos son las estructuras de datos que representan los hechos que se deben rastrear durante la vida de un sujeto. Estas estructuras constituyen el micrologger, es decir, la cadena de acontecimientos.
Cada evento se compone de lo siguiente:
- La solicitud que generó el evento.
- La huella criptográfica del evento anterior para formar la cadena.
- Una serie de metainformación relacionada con el sujeto y el evento.
- Un grupo de firmas diferentes que se agregan a medida que el evento avanza en su ciclo de vida.
Ciclo de vida
La gobernanza determina el procolo por el que los eventos son incorporados al ciclo de vida del sujeto de trazabilidad. El ciclo de vida del evento se compone de 6 etapas, desde su solicitud de generación hasta su distribución.
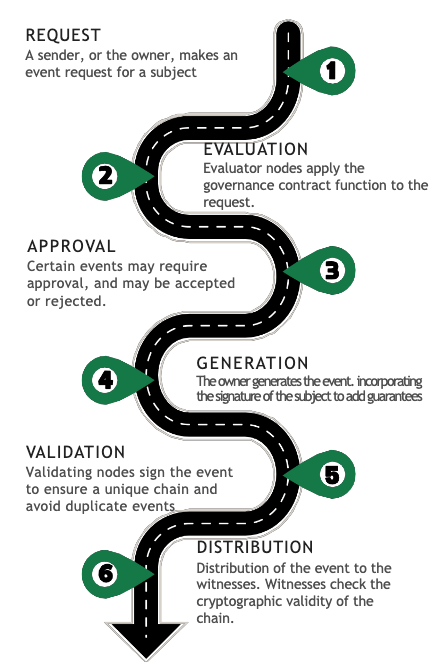
Figure 1: Ciclo de vida.
1. Solicitud
Para cambiar el estado de un sujeto es necesario agregar un evento a su microledger. Para ello, el primer paso es generar una solicitud de evento . En Kore sólo el propietario del sujeto puede generar eventos sobre el mismo . Sin embargo, estos eventos pueden generarse por solicitudes de otros participantes, conocidos como emisores . De esta forma, el titular actúa como organizador de las solicitudes de eventos, que pueden ser generadas por él mismo o por otros participantes.
ATENCIÓN
Al ser el único que puede ingresar eventos en el microledger, el propietario tiene la última palabra sobre si crear o no un evento a partir de una solicitud, incluso si lo envía otro participante. En situaciones en las que sea necesario garantizar que la solicitud ha sido registrada, se deben implementar medidas de seguridad adicionales a las ofrecidas por Kore.Las solicitudes de eventos contienen lo siguiente:
- El tipo de evento a generar.
- La información a incluir en el microledger, por ejemplo, para modificar el estado del sujeto.
- La firma del emisor, que puede ser el propietario del sujeto u otro participante con permisos suficientes.
2. Evaluación
En Kore existen diferentes tipos de eventos y no todos comparten el mismo ciclo de vida. En el caso de los eventos Fact existen 2 pasos adicionales: evaluación y aprobación.
La fase de evaluación corresponde a la ejecución del contrato. Para ello, el titular del sujeto envía la siguiente información a los evaluadores:
- el estado actual del sujeto, ya que los evaluadores no necesitan presenciarla, y por lo tanto pueden no conocer su estado;
- los metadatos del sujeto, como su esquema y espacio de nombres.
Después de recibir la información, el evaluador ejecuta el contrato y devuelve el estado del sujeto modificado al propietario del sujeto, la necesidad o no de aprobación y su firma. El propietario debe recoger tantas firmas de evaluadores como dicta la gobernanza.
3. Aprobación
La evaluación de algunos contratos puede determinar que el resultado, incluso si se ejecuta correctamente, requiere aprobación. Esto significa que, para ser aceptado por los demás participantes, es necesario incluir una serie de firmas adicionales de otros participantes, los aprobadores. Estos aprobadores firman a favor o en contra de una solicitud de evento. Las reglas definidas en la gobernanza indican qué firmas son necesarias para que una petición de evento sea aprobada y, por tanto, para que se genere un evento a partir de esta solicitud.
La decisión de aprobar o no una solicitud puede depender de la participación de un individuo o puede depender de algún sistema de TI, como un proceso de inteligencia empresarial.
4. Generación
El siguiente paso es la generación efectiva del evento. El evento se compone incluyendo la solicitud, la evaluación del contrato, las firmas de los evaluadores y aprobadores, el hash del evento anterior y una serie de metadatos asociados al evento. Luego, el evento se firma con el material criptográfico del sujeto, lo que garantiza que solo el propietario del sujeto pudo generar el evento.
5. Validación
Un evento generado no se puede distribuir directamente. La razón es que los demás participantes en la red no tienen garantía de que el propietario no haya generado versiones diferentes del evento y las haya distribuido según sus propios intereses. Para evitarlo surge la fase de validación. Varios participantes de la red, los validadores, proporcionan su firma al evento, garantizando que existe un único evento. No todas las materias requieren las firmas de los mismos validadores. La gobernanza define qué participantes deben proporcionar sus firmas y cuántas firmas se requieren. El número de firmas dependerá del caso de uso y de la confianza de la red en los miembros que actúan como validadores.
6. Distribución
Una vez que haya suficientes firmas de validación, el evento estará completo y podrá distribuirse al resto de participantes de la red. El propietario envía el evento junto con las firmas de validación a los testigos. Los testigos, una vez comprobada la validez del conjunto, incorporarán el evento al microledger, y borrarán las firmas de validación que tenían almacenadas para el evento anterior.
Tipos de eventos
| Evento | Descripción |
|---|---|
| Start | Inicializa el registro de eventos de un sujeto, estableciendo a los participantes y la gobernanza del libro contable. |
| State | Los registros de estado cambian las propiedades del sujeto, por lo que su estado se modifica. |
| Fact | Hechos relacionados con la función o el entorno del sujeto pero que no modifican sus propiedades. |
| Transfer | Transfiere la propiedad del sujeto a un nuevo propietario. Ocurre una rotación de clave para evitar la manipulación de eventos anteriores por el nuevo propietario. |
| EOL | Evento de fin de vida que finaliza el registro de eventos, evitando nuevas adiciones. |
En cuanto a la estructura y los contenidos de los actos, nos hemos basado en soluciones de diseño reconocidas por la industria 1. El enfoque habitual es estructurar el evento en una cabecera, con una estructura común para todos los eventos, incluyendo sus metadatos, y una carga útil con información específica para cada evento.
Ejemplo
Diagrama generado un evento tipo Fact.
sequenceDiagram
actor Emisor
actor Propietario
actor Evaluador
actor Aprobador
actor Validador
actor Testigo
Note over Propietario: 1 - Fase de Petición
Emisor->>Propietario: Solicitud de evento
Note over Propietario: 2 - Fase de Evaluación
alt Evento Fact
Propietario->>Evaluador: Solicitud de evaluación
Evaluador->>Propietario: Respuesta de evaluación
end
Note over Propietario: 3 - Fase de Aprobación
alt La evaluación del contrato dice que se requiere aprobación
Propietario->>Aprobador: Solicitud de aprobación
Aprobador->>Propietario: Respuesta de aprobación
end
Note over Propietario: 4 - Fase de composición
Propietario->>Propietario: Generación de eventos
Note over Propietario: 5 - Fase de validación
Propietario->>Propietario: Generación de pruebas de validación
Propietario->>Validador: Solicitud de validación
Validador->>Propietario: Respuesta de validación
Note over Propietario: 6 - Fase de distribución
Propietario->>Testigo: Evento
Testigo->>Propietario: ACK
Diagrama generado un evento tipo State.
sequenceDiagram
actor Emisor
actor Propietario
actor Evaluador
actor Aprobador
actor Validador
actor Testigo
Note over Propietario: Fase 1 - Solicitud de cambio de estado(Evento State)
Emisor->>Propietario: Solicita cambio de estado en el sujeto
Note over Propietario: Fase 2 - Evaluación de la solicitud
Propietario->>Evaluador: Solicita evaluación de la solicitud
Evaluador->>Propietario: Devuelve evaluación (positiva o negativa)
alt Evaluación positiva
Note over Propietario: Fase 3 - Aprobación (si es necesario)
alt Aprobación requerida
Propietario->>Aprobador: Solicita aprobación
Aprobador->>Propietario: Devuelve aprobación (positiva o negativa)
end
Note over Propietario: Fase 4 - Incorporación del evento
Propietario->>Propietario: Incorpora el evento al registro de eventos
Note over Propietario: Fase 5 - Validación del evento
Propietario->>Validador: Solicita validación
Validador->>Propietario: Devuelve respuesta de validación
Note over Propietario: Fase 6 - Distribución del evento
Propietario->>Testigo: Envía evento a testigos
Testigo->>Propietario: Confirma recepción del evento
else Evaluación negativa
Note over Propietario: La solicitud es rechazada
end
Referencias
-
Event Processing in Action - Opher Etzion y Peter Niblett (2010). Manning Publications Co., 3 Lewis Street Greenwich, Estados Unidos. ISBN: 978-1-935182-21-4. ↩︎
2.1.6 - Identidad
Descipción de la identidad en Kore Ledger.
Cada participante de una red Kore Ledger tiene un identificador único y una clave privada que le permite firmar las transacciones realizadas. Además, dependiendo de su interés en cada sujeto y su nivel de implicación con la red, cada participante tendrá uno o varios roles diferentes.
Dada la fuerte influencia de KERI1 en nuestro proyecto,la reflexión sobre el modelo de referencia para establecer los identificadores en nuestro protocolo parte del triángulo de Zooko2. Se trata de un trilema que define tres propiedades deseables deseables en los identificadores de un protocolo de red, de las cuales sólo dos pueden estar simultáneamente. Estas propiedades son:
- Con sentido humano: Nombres significativos y memorables (de baja entropía) a los usuarios.
- Seguro: La cantidad de daño que una entidad maliciosa puede infligir al sistema debe ser lo más bajo posible.
- Descentralizado: Los nombres se resuelven correctamente a sus respectivas entidades sin utilizar una autoridad o servicio central.
Aunque ya se han propuesto varias soluciones al trilema, hemos priorizado la descentralización y la seguridad para aplicar en breve un diseño equivalente al Ethereum Name Service . En concreto, en nuestro enfoque hemos considerado tres tipos de identificadores, que a su vez representan tres tipos de material criptográfico:
- Clave pública, el identificador de los roles participantes en la red.
- Resumen de mensajes, el identificador del contenido de los mensajes resultantes de aplicar una función hash a este contenido.
- Firma criptográfica, identificador de las firmas realizadas por los roles en los mensajes, que sirve como prueba verificable.
Este material criptográfico son grandes números binarios, lo que representa un desafío cuando se utilizan como identificadores. La mejor manera de manejar identificadores es a través de una cadena de caracteres y, para la conversión, hemos adoptado la codificación Base64 , que codifica cada 3 bytes de un número binario en 4 caracteres ASCII. Como el material criptográfico que se gestiona no es múltiplo de 3 (32 bytes y 64 bytes), se rellena con un carácter adicional (32 bytes) o dos (64 bytes). Al igual que en KERI, hemos aprovechado estos caracteres adicionales para establecer un código de derivación para determinar el tipo de material, colocando el o los caracteres de derivación al principio.
La siguiente tabla detalla los códigos de derivación admitidos actualmente :
| Código | Tipo de Identificador |
|---|---|
| E | Clave Pública Ed25519 |
| S | Clave Pública Secp256k1 |
| J | Digest Blake3 (256 bits) |
| OJ | Digest Blake3 (512 bits) |
| L | Digest SHA2 (256 bits) |
| OL | Digest SHA2 (512 bits) |
| M | Digest SHA3 (256 bits) |
| OM | Digest SHA3 (512 bits) |
Ya se han incorporado nuevos tipos de material criptográfico en la hoja de ruta, pensando en dispositivos limitados a operaciones con RSA3 o P2564, y la criptografía post-cuántica, como Crystal-Dilithium5. En el caso de RSA o Crystal-Dilithium, estamos tratando con un tamaño binario del material criptográfico que es demasiado grande para ser representado como identificadores, por lo que tendremos que incorporar un mecanismo de derivación diferente.
Referencias
-
KERI White Paper - Samuel L. Smith (2021) “Key Event Receipt Infrastructure (KERI).” ↩︎
-
Zooko’s Triangle - Wikipedia (2022). ↩︎
-
RSA - Rivest, Shamir y Adleman (1978) “A Method for Obtaining Digital Signatures and Public-Key Cryptosystems.” ↩︎
-
NIST - Mehmet Adalier y Antara Teknik (2015) “Efficient and Secure Elliptic Curve Cryptography Implementation of Curve P-256.” ↩︎
-
CRYSTALS-Dilithium - Léo Ducas et al. (2021) “CRYSTALS-Dilithium – Algorithm Specifications and Supporting Documentation (Version 3.1).” ↩︎
2.1.7 - Nodos
Tipos de Nodos
Bootstrap
Son los nodos que con los que establecer conexión de la red de trazabilidad si se dispone de una licencia de acceso. También proporcionan circuitos seguros para comunicar con los nodos efímeros.
Direccionables
Nodos que requieren de una dirección pública. Se puede crear la governanza en ellos para que el efímero emita los eventos correspondientes.
Efímeros
Estos (que normalmente estarán detrás de un NAT/Firewall) serán los encargados de emitir eventos a los nodos Bootstrap.
2.1.8 - Contratos
Contratos Kore Ledger.
Definición
Un contrato en Kore Ledger son las reglas, acuerdos y acciones derivadas de dichos acuerdos que se ejecutan en cada solicitud de evento del ciclo de vida de un sujeto. Del mismo modo que un sujeto tiene siempre un esquema asociado, que define el conjunto de propiedades de su estado, dicho esquema tiene siempre un contrato asociado. Los cambios en su ciclo de vida se producen exclusivamente a través de la ejecución de este contrato.
Estructura
Trabajos futuros
En su definición, nos limitamos exclusivamente al término “contrato”, frente a la denominación utilizada en las tecnologías blockchain de “contrato inteligente”, para ofrecer una mayor precisión sobre su intencionalidad. Los denominados “contratos inteligentes” no son contratos inteligentes y son sólo programas que se ejecutan bajo ciertas condiciones preestablecidas. En nuestro caso, el objetivo es ofrecer una estructura de contrato basada en un lenguaje formal inspirado fundamentalmente en la propuesta FCL (Formal Contract Language) 1.
Referencias
2.2 - Conceptos avanzados
Descripción de los conceptos avanzados.
2.2.1 - Proceso de aprobación del evento
Descripción del proceso de aprobación del evento.
La fase de aprobación consiste en pedir a los aprobadores que voten a favor o en contra de la aplicación de un evento. Este proceso puede automatizarse, pero tiende a ser manual. La respuesta requiere interacción con la API de Kore si está configurada como manual, por lo que requiere un usuario que pueda interactuar con ella y, por lo tanto, suele llevar más tiempo que las otras fases.
Los aprobadores están definidos por la gobernanza, por lo que deben poseerlo para realizar la evaluación, de lo contrario no tendrían acceso al contrato, que a su vez se almacena en el estado del gobierno.
Los aprobadores sólo realizarán la evaluación si la versión de la gobernanza que posee el propietario del sujeto coincide con la del aprobador. Si es inferior o superior, se envía al propietario del sujeto un mensaje adecuado a cada caso.
El proceso de aprobación consta de los siguientes pasos:
- El propietario del sujeto verifica si la solicitud de evento requiere aprobación observando la respuesta de los evaluadores.
- Si la solicitud lo requiere, se envía una solicitud de aprobación a los diferentes aprobadores.
- Una vez que cada aprobador tenga la solicitud, podrá votar, tanto a favor como en contra, y la enviará de vuelta al propietario del sujeto.
- Cada vez que el titular reciba un voto comprobará lo siguiente:
- Hay suficientes votos positivos para que la solicitud sea aceptada.
- Hay tantos votos negativos que es imposible que se apruebe la solicitud. En ambos casos, el propietario generará un evento. En el caso de que la votación no haya sido exitosa, se generará el evento pero no producirá cambios en el estado del sujeto, quedando con fines meramente informativos.
ATENCIÓN
Es importante recordar que el propietario del sujeto es el único que puede forzar un cambio efectivo en un sujeto. Por tanto, el propietario, tras el proceso de aprobación, podría decidir si incluye o no el evento en la cadena. Esto no seguiría el comportamiento estándar definido por Kore, pero no rompería la compatibilidad.sequenceDiagram
actor Owner
actor Evaluator
actor Approver 1
actor Approver 2
actor Approver 3
%% Invocador->>Owner: Submit an event request
Note over Evaluator: Evaluation phase
alt Need for approval detected
Owner->Approver 3: Transmit approval request to all approvers
Approver 1-->>Owner: Receive
Approver 2-->>Owner: Receive
Approver 3-->>Owner: Not receive
Note over Owner: Wait
Approver 1->>Owner: Vote yes
Approver 2->>Owner: vote no
Note over Owner: Receive vote request
Owner->>Approver 3: Transmit request
Approver 3-->>Owner: Receive
Note over Owner: Wait
Approver 3->>Owner: Vote yes
Note over Owner: Receive vote request
end
alt Positive quorum
Owner->>Owner: Generate event and update subject
else Negative quorum
Owner->>Owner: Generate event
end
Owner->Approver 3: Event goes to the validation phase
2.2.2 - Proceso de evaluación de eventos
Descripción del proceso de evaluación del evento.
La fase de evaluación consiste en que el propietario del sujeto envía una solicitud de evaluación a los evaluadores, justo después de que el emisor generó una solicitud de evento con el tipo de evento y su contenido. Actualmente, la evaluación sólo está presente en eventos de tipo Fact, en los otros tipos se omite. Estos acontecimientos afectan a un determinado sujeto para establecer un Fact que puede modificar o no el estado del sujeto. También se envía un contexto que contiene la información necesaria para que los evaluadores ejecuten el contrato que contiene la lógica de evaluación de nuestro sujeto, como el estado anterior, si el emisor es el propietario del sujeto, etc. Este es el caso porque los evaluadores no necesariamente tienen una copia del sujeto, por lo que necesitan estos datos, que incluyen todo lo necesario para la ejecución del contrato.
Los evaluadores están definidos en la gobernanza, por lo que deben poseerlo para poder realizar la evaluación, de lo contrario no tendrían acceso al contrato, que a su vez se almacena en el estado del gobierno.
El resultado de aplicar el evento al sujeto en términos de modificación de propiedad lo realizan los evaluadores. Tienen la capacidad de compilar y ejecutar contratos compilados en WebAssembly.
La solicitud de evento de Fact contiene la información necesaria para ejecutar una de las funciones del contrato (o no, en cuyo caso se produce una evaluación fallida y se notifica al propietario del sujeto). La respuesta incluye si la evaluación fue exitosa o fallida, si es necesario pasar por la fase de aprobación y el JSON patch que, aplicado al estado del sujeto, producirá el cambio de estado, así como el hash del estado actualizado.
La respuesta de los evaluadores es firmada por ellos para que los testigos puedan verificar que se ha alcanzado el quórum en la fase de evaluación y que han firmado los evaluadores correctos.
Los evaluadores sólo realizarán la evaluación si la versión de la gobernanza que tiene el propietario del sujeto coincide con la del evaluador. Si es inferior o superior, se envía un mensaje adecuado a cada caso al propietario del sujeto.
Para los emisores, cuando se actualiza la gobernanza al que está asignado el sujeto, se debe reiniciar el proceso desde el inicio de la evaluación, ya sea que aún se encontrara en la fase de evaluación o ya en la fase de aprobación. Esto se debe a que los eventos deben evaluarse/aprobarse con la última versión de gobernanza disponible.
sequenceDiagram
actor Owner as Owner
actor Evaluator1 as Evaluator 1
actor Evaluator2 as Evaluator 2
actor Evaluator3 as Evaluator 3
Owner->>Evaluator1: Generate Evaluation Request
Owner->>Evaluator2: Generate Evaluation Request
Owner->>Evaluator3: Generate Evaluation Request
alt Governance Access Granted and Governance Version Matches
Evaluator1->>Evaluator1: Check Governance and Execute Contract
Evaluator2->>Evaluator2: Check Governance and Execute Contract
Evaluator3->>Evaluator3: Check Governance and Execute Contract
alt Evaluation Successful
Evaluator1->>Owner: Return Evaluation Response and Evaluator's Signature
Evaluator2->>Owner: Return Evaluation Response and Evaluator's Signature
Evaluator3->>Owner: Return Evaluation Response and Evaluator's Signature
else Evaluation Failed
Evaluator1->>Owner: Return Evaluation Response (with failed status) and Evaluator's Signature
Evaluator2->>Owner: Return Evaluation Response (with failed status) and Evaluator's Signature
Evaluator3->>Owner: Return Evaluation Response (with failed status) and Evaluator's Signature
end
else Governance Access Denied or Governance Version Mismatch
Evaluator1->>Owner: Send Appropriate Message
Evaluator2->>Owner: Send Appropriate Message
Evaluator3->>Owner: Send Appropriate Message
Owner->>Owner: Restart Evaluation Process
end
2.2.3 - Proceso de validación de eventos
Descripción del proceso de validación de eventos.
El proceso de validación es el último paso antes de lograr un evento válido que pueda incorporarse a la cadena del sujeto. El objetivo de esta fase es asegurar la unicidad de la cadena del sujeto. Se basa en la recogida de firmas de los validadores, que están definidas en la gobernanza. No produce un cambio en el evento en sí, ya que las firmas no están incluidas en el evento, pero son necesarias para validarlo ante los ojos de los testigos. Cabe señalar que para que la unicidad de la cadena sea plenamente efectiva, el quórum de validación debe estar formado por la mayoría de validadores. Esto se debe a que de no ser así se podrían validar varias cadenas con validadores diferentes para cada una si la suma del porcentaje de firmas para todos los quórumes no supera el 100%.
Prueba de validación
Lo que firman los validadores se llama prueba de validación, el evento en sí no está firmado directamente. Esto se hace para garantizar la privacidad de los datos del evento y al mismo tiempo agregar información adicional que permita que el proceso de validación sea más seguro. A su vez, cuando los propietarios de los sujetos envían la prueba a los validadores, ésta también es firmada con el material criptográfico del sujeto. Tiene esta forma:
pub struct ValidationProof {
/// El identificador del sujeto que está siendo validado.
pub subject_id: DigestIdentifier,
/// El identificador del esquema utilizado para validar el sujeto.
pub schema_id: String,
/// El espacio de nombres del sujeto que está siendo validado.
pub namespace: String,
/// El nombre del sujeto que está siendo validado.
pub name: String,
/// El identificador de la clave pública del sujeto que está siendo validado.
pub subject_public_key: KeyIdentifier,
/// El identificador del contrato de gobernanza asociado con el sujeto que está siendo validado.
pub governance_id: DigestIdentifier,
/// La versión del contrato de gobernanza que creó el sujeto que está siendo validado.
pub genesis_governance_version: u64,
/// El número de secuencia del sujeto que está siendo validado.
pub sn: u64,
/// El identificador del evento previo en la cadena de validación.
pub prev_event_hash: DigestIdentifier,
/// El identificador del evento actual en la cadena de validación.
pub event_hash: DigestIdentifier,
/// La versión del contrato de gobernanza utilizado para validar el sujeto.
pub governance_version: u64,
}
Datos como la versión de la gobernanza(que denominaremos sn), que se usa para verificar que el voto solo debe devolverse si coincide con la versión de la gobernanza del sujeto para el validador, y la clave_pública(que denominaremos subject_id) es la que se usa para validar la firma del propietario de la próxima prueba de validación que llegue al validador.
Si el validador tiene la prueba anterior, puede validar ciertos aspectos, como que el prev_event_hash del nuevo coincida con el event_hash del anterior. La base de datos de los validadores siempre almacenará la última prueba que firmaron para cada sujeto. Esto les permite nunca firmar dos pruebas para el mismo suject_id y sn pero con otros datos diferentes (excepto la sn). Esto garantiza la unicidad de la cadena. La capacidad de cambiar la versión de la gobernanza se debe a lo que discutimos anteriormente: si un validador recibe una prueba con una versión de gobernanza diferente a la suya, no debe firmarla. Por lo tanto, ante actualizaciones de la gobernanza en medio de un proceso de validación, el propietario deberá reiniciar dicho proceso, adaptando la versión de la gobernanza de la prueba a la nueva.
Otro punto interesante es el caso en el que los validadores no cuentan con la prueba anterior para validar la nueva. No existe un escenario donde los validadores siempre tengan la prueba anterior, ya que incluso cuando el quórum requiere el 100% de las firmas, si un cambio de gobernanza agrega un nuevo validador, no tendrá la prueba anterior. Es por esto que cuando se solicita una validación se debe enviar:
pub struct ValidationEvent {
pub proof: ValidationProof,
pub subject_signature: Signature,
pub previous_proof: Option<ValidationProof>,
pub prev_event_validation_signatures: HashSet<Signature>,
}
La prueba anterior es opcional porque no existe en el caso del evento 0. El hashset de firmas incluye todas las firmas de los validadores que permiten que la prueba anterior haya alcanzado el quórum. Con estos datos, el validador puede confiar en la prueba previa que se le envía si no la dispone previamente.
La comunicación para solicitar validación y enviar validación es directa entre el propietario y el validador y se realiza de forma asíncrona.
Cadena correcta
Como mencionamos anteriormente, la fase de validación se centra en lograr una cadena única, pero no en si esta cadena es correcta. Esta responsabilidad recae en última instancia en los testigos, que son los interesados del sujeto. Los validadores no necesitan tener la cadena actualizada del sujeto para validar la siguiente prueba, ya que las pruebas son autocontenidas y como máximo requieren información de la prueba anterior. Pero nada impide que un propietario malicioso envíe datos erróneos en la prueba, los validadores no se darán cuenta porque no tienen el contexto necesario y firmarán como si todo estuviera correcto. Los testigos, sin embargo, sí tienen el sujeto actualizado, por lo que pueden detectar este tipo de engaños. Si algo así sucediera, los testigos son los encargados de denunciarlo y el sujeto sería bloqueado.
Sequence Diagram
sequenceDiagram
actor Owner as Owner
actor Validator1 as Validator 1
actor Validator2 as Validator 2
actor Validator3 as Validator 3
actor Witness as Witness
Owner->>Validator1: Send ValidationEvent
Owner->>Validator2: Send ValidationEvent
Owner->>Validator3: Send ValidationEvent
alt Governance Version Matches and Proofs are Valid
Validator1->>Validator1: Inspect Governance, Check Last Proof and Signatures
Validator2->>Validator2: Inspect Governance, Check Last Proof and Signatures
Validator3->>Validator3: Inspect Governance, Check Last Proof and Signatures
Validator1->>Owner: Return ValidationEventResponse with Validator's Signature
Validator2->>Owner: Return ValidationEventResponse with Validator's Signature
Validator3->>Owner: Return ValidationEventResponse with Validator's Signature
else Governance Version Mismatch or Proofs are Invalid
Validator1->>Owner: Send Appropriate Message (if applicable)
Validator2->>Owner: Send Appropriate Message (if applicable)
Validator3->>Owner: Send Appropriate Message (if applicable)
Note over Validator1,Validator3: End Process (No Response)
end
Owner->>Owner: Collect Enough Validator Signatures
Owner->>Witness: Create Event in Ledger and Distribute
2.3 - Glosario
Definición de conceptos
A
Aprobador
Algunas solicitudes de eventos requieren una serie de firmas para ser aprobadas y pasar a formar parte del microledger del sujeto. Esta recogida de firmas es un proceso de votación donde los participantes pueden votar a favor o en contra. Estos participantes, definidos en la gobernanza, son los aprobadores.
B
Bootstrap
Es parte del protocolo Kademlia. Es el nombre del nodo que se utiliza para todos los nodos de noticias que quieren unirse a la red P2P para ser descubiertos por todos los demás.
Blockchain
Blockchain es un subtipo de DLT, y por tanto podemos decir que es fundamentalmente una base de datos distribuida, descentralizada, compartida e inmutable.
C
Criptografía
Es la práctica y el estudio de técnicas para la comunicación segura en presencia de conductas adversas.
D
DLT
- Inmutable y resistente a manipulaciones. Implementa mecanismos de seguridad criptográfica que evitan que su contenido sea alterado, o al menos, si algún nodo intenta modificar la información, puede ser detectado y bloqueado fácilmente. Significa “Tecnología de contabilidad distribuida”. Una DLT no es más que una base de datos que actúa como un libro mayor pero que además tiene, en mayor o menor medida, las siguientes características:
- Está distribuido y descentralizado.
- Compartido.
- Inmutable y resistente a manipulaciones.
Dispositivos perimetrales
Un dispositivo que proporciona un punto de entrada a las redes centrales de la empresa o del proveedor de servicios.
E
Evento
El incidente que se produce cuando se pretende modificar el estado de un sujeto.
F
Fog Computing
Es una arquitectura que utiliza dispositivos periféricos para llevar a cabo una cantidad sustancial de computación, almacenamiento y comunicación localmente y enrutada a través de la red troncal de Internet.
Fog GateWay
Sinónimo de dispositivos perimetrales. Un dispositivo que proporciona un punto de entrada a las redes centrales de la empresa o del proveedor de servicios.
G
Gobernanza
La gobernanza es una estructura a través de la cual un participante o usuario de un sistema acepta utilizar el sistema. Podemos decir fácilmente que hay tres principios que dictan la gobernanza. Estos principios incluyen:
- Gobernando
- Reglas
- Participantes
k
Kademlia
Es un DTL que define la estructura de la red y cómo se intercambia la información mediante búsquedas de nodos. Las comunicaciones se realizan mediante UDP y, en el proceso, se crea una red superpuesta de nodos identificados por una ID. Esta ID no solo es útil para identificar el nodo sino también para determinar la distancia entre dos nodos para que el protocolo pueda determinar con quién debe comunicarse.
Kore
Significa “Seguimiento (autónomo) de eventos de procedencia y ciclo de vida”. Kore es una solución DLT autorizada para la trazabilidad de activos y procesos.
Kore Node
Cliente oficial para crear un Nodo Kore. Es la forma más sencilla de trabajar con Kore, ya que es una aplicación de consola simple que proporciona todo lo necesario para construir un nodo (Kore Base, API Rest y diferentes configuraciones de mecanismos).
Kore Base
Es la biblioteca que implementa la mayor parte de la funcionalidad de Kore (creación y gestión de temas y sus microledgers asociados, implementación del protocolo P2P para la comunicación entre nodos y persistencia de la base de datos). Cualquier aplicación que quiera formar parte de una red Kore deberá hacer uso de esta biblioteca desde la API que expone.
Kore Network
Es la red P2P creada por todos los nodos de Kore en funcionamiento.
L
Ledger
Un libro mayor es un concepto contable que básicamente define un libro mayor en el que siempre se agrega información, generalmente en forma de transacciones.
M
Microledger
El microledger es un conjunto de eventos encadenados entre sí mediante mecanismos criptográficos.
Multiaddr
Una multiaddress (a menudo abreviada multiaddr) es una convención para codificar múltiples capas de información de direcciones en una única estructura de ruta “preparada para el futuro”. Ofrece codificaciones legibles por humanos y optimizadas para máquinas de protocolos de superposición y transporte comunes y permite combinar y utilizar juntas muchas capas de direccionamiento.
N
Nodo
Es una computadora conectada a otras computadoras que sigue reglas y comparte información.
P
P2P
Es una arquitectura de aplicación distribuida que divide tareas o cargas de trabajo entre pares igualmente privilegiados y participantes equipotentes en la red que la conforman.
S
Sujeto
Los sujetos son una entidad lógica o proceso que almacena todos los datos necesarios para definirse y que emite eventos a lo largo de su ciclo de vida con un orden de emisión determinado por él mismo.
T
Transacción
Es un acuerdo o comunicación entre 2 entidades diferentes para aceptar un cambio en el estado de un sujeto.
Testigo
Participante interesado en tener una copia del sujeto y la información que almacena.
V
Validador
El validador es un participante de la red que proporciona la firma de seguridad al sujeto. El validador mantiene una copia completa de los sujetos que valida y se compromete con la red a no aceptar más de una versión del mismo evento.
3 - Aprende
Aprende sobre la tecnología Kore Ledger.
3.1 - Gobernanza
Documentación sobre las gobernanzas.
3.1.1 - Estructura de la gobernanza
Estructura que conforma una gobernanza.
En esta página describiremos la estructura y configuración de gobierno. Si desea saber más sobre qué es una gobernanza visite la página Gobernanza.
GOVERNANZA DE EJEMPLO
Haga clic para ver un ejemplo de gobernanza completo. Cada sección se analizará por separado en las siguientes secciones.
{
"members": [
{
"name": "Company1",
"id": "ED8MpwKh3OjPEw_hQdqJixrXlKzpVzdvHf2DqrPvdz7Y"
},
{
"name": "Company2",
"id": "EXjEOmKsvlXvQdEz1Z6uuDO_zJJ8LNDuPi6qPGuAwePU"
}
],
"schemas": [
{
"id": "Test",
"schema": {
"type": "object",
"additionalProperties": false,
"required": ["temperature", "location"],
"properties": {
"temperatura": {
"type": "integer"
},
"localizacion": {
"type": "string"
}
}
},
"initial_value": {
"temperatura": 0,
"localizacion": ""
},
"contract": {
"raw": "dXNlIHNlcmRlOjp7U2VyaWFsaXplLCBEZXNlcmlhbGl6ZX07Cgptb2Qgc2RrOwoKI1tkZXJpdmUoU2VyaWFsaXplLCBEZXNlcmlhbGl6ZSwgQ2xvbmUpXQpzdHJ1Y3QgU3RhdGUgewogIHB1YiBvbmU6IHUzMiwKICBwdWIgdHdvOiB1MzIsCiAgcHViIHRocmVlOiB1MzIKfQoKI1tkZXJpdmUoU2VyaWFsaXplLCBEZXNlcmlhbGl6ZSldCmVudW0gU3RhdGVFdmVudCB7CiAgTW9kT25lIHsgZGF0YTogdTMyIH0sCiAgTW9kVHdvIHsgZGF0YTogdTMyIH0sCiAgTW9kVGhyZWUgeyBkYXRhOiB1MzIgfSwKICBNb2RBbGwgeyBvbmU6IHUzMiwgdHdvOiB1MzIsIHRocmVlOiB1MzIgfQp9CgojW25vX21hbmdsZV0KcHViIHVuc2FmZSBmbiBtYWluX2Z1bmN0aW9uKHN0YXRlX3B0cjogaTMyLCBldmVudF9wdHI6IGkzMiwgaXNfb3duZXI6IGkzMikgLT4gdTMyIHsKICAgIHNkazo6ZXhlY3V0ZV9jb250cmFjdChzdGF0ZV9wdHIsIGV2ZW50X3B0ciwgaXNfb3duZXIsIGNvbnRyYWN0X2xvZ2ljKQp9CgpmbiBjb250cmFjdF9sb2dpYygKICBjb250ZXh0OiAmc2RrOjpDb250ZXh0PFN0YXRlLCBTdGF0ZUV2ZW50PiwKICBjb250cmFjdF9yZXN1bHQ6ICZtdXQgc2RrOjpDb250cmFjdFJlc3VsdDxTdGF0ZT4sCikgewogIGxldCBzdGF0ZSA9ICZtdXQgY29udHJhY3RfcmVzdWx0LmZpbmFsX3N0YXRlOwogIG1hdGNoIGNvbnRleHQuZXZlbnQgewogICAgICBTdGF0ZUV2ZW50OjpNb2RPbmUgeyBkYXRhIH0gPT4gewogICAgICAgIHN0YXRlLm9uZSA9IGRhdGE7CiAgICAgIH0sCiAgICAgIFN0YXRlRXZlbnQ6Ok1vZFR3byB7IGRhdGEgfSA9PiB7CiAgICAgICAgc3RhdGUudHdvID0gZGF0YTsKICAgICAgfSwKICAgICAgU3RhdGVFdmVudDo6TW9kVGhyZWUgeyBkYXRhIH0gPT4gewogICAgICAgIHN0YXRlLnRocmVlID0gZGF0YTsKICAgICAgfSwKICAgICAgU3RhdGVFdmVudDo6TW9kQWxsIHsgb25lLCB0d28sIHRocmVlIH0gPT4gewogICAgICAgIHN0YXRlLm9uZSA9IG9uZTsKICAgICAgICBzdGF0ZS50d28gPSB0d287CiAgICAgICAgc3RhdGUudGhyZWUgPSB0aHJlZTsKICAgICAgfQogIH0KICBjb250cmFjdF9yZXN1bHQuc3VjY2VzcyA9IHRydWU7Cn0="
}
}
],
"policies": [
{
"id": "Test",
"validate": {
"quorum": {
"PROCENTAJE": 0.5
}
},
"evaluate": {
"quorum": "MAJORITY"
},
"approve": {
"quorum": {
"FIXED": 1
}
}
},
{
"id": "governance",
"validate": {
"quorum": {
"PROCENTAJE": 0.5
}
},
"evaluate": {
"quorum": "MAJORITY"
},
"approve": {
"quorum": {
"FIXED": 1
}
}
}
],
"roles": [
{
"who": "MEMBERS",
"namespace": "",
"role": "CREATOR",
"schema": {
"ID": "Test"
}
},
{
"who": "MEMBERS",
"namespace": "",
"role": "WITNESS",
"schema": {
"ID": "Test"
}
},
{
"who": "MEMBERS",
"namespace": "",
"role": "EVALUATOR",
"schema": "ALL"
},
{
"who": {
"NAME": "Company1"
},
"namespace": "",
"role": "APPROVER",
"schema": "ALL"
}
]
}
Miembros
Esta propiedad nos permite definir las condiciones que se deben cumplir en las diferentes fases de generación de un evento que requiere la participación de diferentes miembros, como aprobación, evaluación y validación.
- name: Nombre corto y coloquial por el que se conoce al nodo en la red. No tiene otra función que la descriptiva. No actúa como un identificador único dentro de la gobernanza.
- id: Corresponde al ID del controlador del nodo. Actúa como identificador único dentro de la red y corresponde a la clave pública criptográfica del nodo.
Esquemas
Define la lista de esquemas que se permite utilizar en los sujetos asociados con la gobernanza. Cada esquema incluye las siguientes propiedades:
- id: Identificador único del esquema.
- schema: Descripción del esquema en formato JSON-Schema.
- initial_value: Objeto JSON que representa el estado inicial de un sujeto recién creado para este esquema.
- contract: El contrato compilado en Raw String base 64.
Rols
En este apartado definimos quiénes son los encargados de dar su consentimiento para que el evento avance por las diferentes fases de su ciclo de vida (evaluación, aprobación y validación), y por otro lado también sirve para indicar quiénes pueden realizar determinadas acciones (creación de sujetos e invocación externa).
- who: Indica a quién afecta el Rol, puede ser un id específico (clave pública), un miembro de la gobernanza identificado por su nombre, todos los miembros, tanto miembros como externos, o solo externos.
- ID{ID}: Clave pública del miembro.
- NAME{NAME}: Nombre del miembro.
- MEMBERS: Todos los miembros.
- ALL: Todos los socios y externos.
- NOT_MEMBERS: Todos los externos.
- namespace: Hace que el rol en cuestión solo sea válido si coincide con el espacio de nombres del sujeto para el cual se está obteniendo la lista de firmas o permisos. Si no está presente o está vacío, se supone que se aplica universalmente, como si fuese el comodín
*. Por el momento, no admitimos comodines complejos, pero implícitamente, si configuramos un espacio de nombres, abarca todo lo que se encuentra debajo de él. Por ejemplo:- open equivale a
open*, pero no aopen. - open.dev es equivalente a
open.dev*, pero no aopen.dev - Si está vacío, equivale a todo, es decir,
*.
- open equivale a
- role: Indica a qué fase afecta:
- VALIDATOR: Para la fase de validación.
- CREATOR: Indica quién puede crear sujetos de este tipo.
- ISSUER: Indica quién puede realizar la invocación externa de este tipo.
- WITNESS: Indica quién es el testigo del sujeto.
- APPROVER: Indica quiénes son los aprobadores del sujeto. Requerido para la fase de aprobación.
- EVALUATOR: Indica quiénes son los evaluadores del sujeto. Requerido para la fase de evaluación.
- esquema: Indica qué esquemas se ven afectados por el rol. Se pueden especificar por su id, todos o aquellos que no son de gobernanza.
- ID{ID}: identificador único del esquema.
- NOT_GOVERNANCE: Todos los esquemas excepto el de gobernanza.
- ALL: Todos los esquemas.
Políticas
Esta propiedad establece los permisos de los usuarios previamente definidos en la sección de miembros, otorgándoles roles respecto a los esquemas que hayan definido. Las políticas se definen de forma independiente para cada esquema definido en la gobernanza.
- approve: Define quiénes son los aprobadores de los sujetos que se crean con ese esquema. Asimismo, el quórum requerido para considerar aprobado un evento.
- evaluate: Define quiénes son los evaluadores de los sujetos que se crean con ese esquema. Asimismo, el quórum requerido para considerar evaluado un evento.
- validate: Define quiénes son los validadores para los sujetos que se crean con ese esquema. Asimismo, el quórum requerido para considerar un evento como validado.
Estos datos lo que definen es el tipo de quórum que se debe alcanzar para que el evento pase esta fase. Hay 3 tipos de quórum:
- MAJORITY: Esta es la más sencilla, significa que la mayoría, es decir más del 50% de los votantes deben firmar la petición. Siempre se redondea hacia arriba, por ejemplo, en el caso de que haya 4 votantes, se alcanzaría el quórum de MAYORÍA cuando 3 den su firma.
- FIXED{fixed}: Es bastante sencillo, significa que un número fijo de votantes debe firmar la petición. Por ejemplo, si se especifica un quórum FIJO de 3, este quórum se alcanzará cuando 3 votantes hayan firmado la petición.
- PERCENTAGE{percentage}: Este es un quórum que se calcula en base a un porcentaje de los votantes. Por ejemplo, si se especifica un quórum de 0,5, este quórum se alcanzará cuando el 50% de los votantes hayan firmado la petición. Siempre se redondea.
En caso de que una política no se resuelva para algún miembro, se devolverá al propietario del gobierno. Esto permite, por ejemplo, que luego de la creación de la gobernanza, cuando aún no haya miembros declarados, el propietario pueda evaluar, aprobar y validar los cambios.
ATENCIÓN
Es necesario especificar los permisos de todos los esquemas que se definen, no existe una asignación predeterminada. Debido a esto, también es necesario especificar los permisos del esquema de gobernanza.3.1.2 - Esquema y contrato de la gobernanza
Esquema y contrato de la gobernanza.
Las gobernanzas en Kore son temas especiales. Las gobernanzas tienen un esquema y un contrato específicos definidos dentro del código Kore. Este es el caso porque es necesaria una configuración previa. Este esquema y contrato deben ser los mismos para todos los participantes de una red; de lo contrario, pueden ocurrir fallos porque se espera un resultado diferente o el esquema es válido para un participante pero no para otro. Este esquema y contrato no aparecen explícitamente en la gobernanza misma, pero están dentro de Kore y no pueden modificarse.
ESQUEMA DE LA GOBERNANZA
Click para ver el esquema completo de la gobernanza.
{
"$defs": {
"role": {
"type": "string",
"enum": ["VALIDATOR", "CREATOR", "ISSUER", "WITNESS", "APPROVER", "EVALUATOR"]
},
"quorum": {
"oneOf": [
{
"type": "string",
"enum": ["MAJORITY"]
},
{
"type": "object",
"properties": {
"FIXED": {
"type": "number",
"minimum": 1,
"multipleOf": 1
}
},
"required": ["FIXED"],
"additionalProperties": false
},
{
"type": "object",
"properties": {
"PERCENTAGE": {
"type": "number",
"minimum": 0,
"maximum": 1
}
},
"required": ["PERCENTAGE"],
"additionalProperties": false
}
]
}
},
"type": "object",
"additionalProperties": false,
"required": [
"members",
"schemas",
"policies",
"roles"
],
"properties": {
"members": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"id": {
"type": "string",
"format": "keyidentifier"
}
},
"required": [
"id",
"name"
],
"additionalProperties": false
}
},
"roles": {
"type": "array",
"items": {
"type": "object",
"properties": {
"who": {
"oneOf": [
{
"type": "object",
"properties": {
"ID": {
"type": "string"
}
},
"required": ["ID"],
"additionalProperties": false
},
{
"type": "object",
"properties": {
"NAME": {
"type": "string"
}
},
"required": ["NAME"],
"additionalProperties": false
},
{
"const": "MEMBERS"
},
{
"const": "ALL"
},
{
"const": "NOT_MEMBERS"
}
]
},
"namespace": {
"type": "string"
},
"role": {
"$ref": "#/$defs/role"
},
"schema": {
"oneOf": [
{
"type": "object",
"properties": {
"ID": {
"type": "string"
}
},
"required": ["ID"],
"additionalProperties": false
},
{
"const": "ALL"
},
{
"const": "NOT_GOVERNANCE"
}
]
}
},
"required": ["who", "role", "schema", "namespace"],
"additionalProperties": false
}
},
"schemas": {
"type": "array",
"minItems": 0,
"items": {
"type": "object",
"properties": {
"id": {
"type": "string"
},
"schema": {
"$schema": "http://json-schema.org/draft/2020-12/schema",
"$id": "http://json-schema.org/draft/2020-12/schema",
"$vocabulary": {
"http://json-schema.org/draft/2020-12/vocab/core": true,
"http://json-schema.org/draft/2020-12/vocab/applicator": true,
"http://json-schema.org/draft/2020-12/vocab/unevaluated": true,
"http://json-schema.org/draft/2020-12/vocab/validation": true,
"http://json-schema.org/draft/2020-12/vocab/meta-data": true,
"http://json-schema.org/draft/2020-12/vocab/format-annotation": true,
"http://json-schema.org/draft/2020-12/vocab/content": true
},
"$dynamicAnchor": "meta",
"title": "Core and validation specifications meta-schema",
"allOf": [
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/core",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/core": true
},
"$dynamicAnchor": "meta",
"title": "Core vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"$id": {
"$ref": "#/$defs/uriReferenceString",
"$comment": "Non-empty fragments not allowed.",
"pattern": "^[^#]*#?$"
},
"$schema": {
"$ref": "#/$defs/uriString"
},
"$ref": {
"$ref": "#/$defs/uriReferenceString"
},
"$anchor": {
"$ref": "#/$defs/anchorString"
},
"$dynamicRef": {
"$ref": "#/$defs/uriReferenceString"
},
"$dynamicAnchor": {
"$ref": "#/$defs/anchorString"
},
"$vocabulary": {
"type": "object",
"propertynames": {
"$ref": "#/$defs/uriString"
},
"additionalProperties": {
"type": "boolean"
}
},
"$comment": {
"type": "string"
},
"$defs": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
}
}
},
"$defs": {
"anchorString": {
"type": "string",
"pattern": "^[A-Za-z_][-A-Za-z0-9._]*$"
},
"uriString": {
"type": "string",
"format": "uri"
},
"uriReferenceString": {
"type": "string",
"format": "uri-reference"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/applicator",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/applicator": true
},
"$dynamicAnchor": "meta",
"title": "Applicator vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"prefixItems": {
"$ref": "#/$defs/schemaArray"
},
"items": {
"$dynamicRef": "#meta"
},
"contains": {
"$dynamicRef": "#meta"
},
"additionalProperties": {
"$dynamicRef": "#meta"
},
"properties": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"default": {}
},
"patternProperties": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"propertynames": {
"format": "regex"
},
"default": {}
},
"dependentschemas": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"default": {}
},
"propertynames": {
"$dynamicRef": "#meta"
},
"if": {
"$dynamicRef": "#meta"
},
"then": {
"$dynamicRef": "#meta"
},
"else": {
"$dynamicRef": "#meta"
},
"allOf": {
"$ref": "#/$defs/schemaArray"
},
"anyOf": {
"$ref": "#/$defs/schemaArray"
},
"oneOf": {
"$ref": "#/$defs/schemaArray"
},
"not": {
"$dynamicRef": "#meta"
}
},
"$defs": {
"schemaArray": {
"type": "array",
"minItems": 1,
"items": {
"$dynamicRef": "#meta"
}
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/unevaluated",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/unevaluated": true
},
"$dynamicAnchor": "meta",
"title": "Unevaluated applicator vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"unevaluatedItems": {
"$dynamicRef": "#meta"
},
"unevaluatedProperties": {
"$dynamicRef": "#meta"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/validation",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/validation": true
},
"$dynamicAnchor": "meta",
"title": "validation vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"type": {
"anyOf": [
{
"$ref": "#/$defs/simpleTypes"
},
{
"type": "array",
"items": {
"$ref": "#/$defs/simpleTypes"
},
"minItems": 1,
"uniqueItems": true
}
]
},
"const": true,
"enum": {
"type": "array",
"items": true
},
"multipleOf": {
"type": "number",
"exclusiveMinimum": 0
},
"maximum": {
"type": "number"
},
"exclusiveMaximum": {
"type": "number"
},
"minimum": {
"type": "number"
},
"exclusiveMinimum": {
"type": "number"
},
"maxLength": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minLength": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"pattern": {
"type": "string",
"format": "regex"
},
"maxItems": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minItems": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"uniqueItems": {
"type": "boolean",
"default": false
},
"maxContains": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minContains": {
"$ref": "#/$defs/nonNegativeInteger",
"default": 1
},
"maxProperties": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minProperties": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"required": {
"$ref": "#/$defs/stringArray"
},
"dependentRequired": {
"type": "object",
"additionalProperties": {
"$ref": "#/$defs/stringArray"
}
}
},
"$defs": {
"nonNegativeInteger": {
"type": "integer",
"minimum": 0
},
"nonNegativeIntegerDefault0": {
"$ref": "#/$defs/nonNegativeInteger",
"default": 0
},
"simpleTypes": {
"enum": [
"array",
"boolean",
"integer",
"null",
"number",
"object",
"string"
]
},
"stringArray": {
"type": "array",
"items": {
"type": "string"
},
"uniqueItems": true,
"default": []
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/meta-data",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/meta-data": true
},
"$dynamicAnchor": "meta",
"title": "Meta-data vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"title": {
"type": "string"
},
"description": {
"type": "string"
},
"default": true,
"deprecated": {
"type": "boolean",
"default": false
},
"readOnly": {
"type": "boolean",
"default": false
},
"writeOnly": {
"type": "boolean",
"default": false
},
"examples": {
"type": "array",
"items": true
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/format-annotation",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/format-annotation": true
},
"$dynamicAnchor": "meta",
"title": "Format vocabulary meta-schema for annotation results",
"type": [
"object",
"boolean"
],
"properties": {
"format": {
"type": "string"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/content",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/content": true
},
"$dynamicAnchor": "meta",
"title": "content vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"contentEncoding": {
"type": "string"
},
"contentMediaType": {
"type": "string"
},
"contentschema": {
"$dynamicRef": "#meta"
}
}
}
],
"type": [
"object",
"boolean"
],
"$comment": "This meta-schema also defines keywords that have appeared in previous drafts in order to prevent incompatible extensions as they remain in common use.",
"properties": {
"definitions": {
"$comment": "\"definitions\" has been replaced by \"$defs\".",
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"deprecated": true,
"default": {}
},
"dependencies": {
"$comment": "\"dependencies\" has been split and replaced by \"dependentschemas\" and \"dependentRequired\" in order to serve their differing semantics.",
"type": "object",
"additionalProperties": {
"anyOf": [
{
"$dynamicRef": "#meta"
},
{
"$ref": "meta/validation#/$defs/stringArray"
}
]
},
"deprecated": true,
"default": {}
},
"$recursiveAnchor": {
"$comment": "\"$recursiveAnchor\" has been replaced by \"$dynamicAnchor\".",
"$ref": "meta/core#/$defs/anchorString",
"deprecated": true
},
"$recursiveRef": {
"$comment": "\"$recursiveRef\" has been replaced by \"$dynamicRef\".",
"$ref": "meta/core#/$defs/uriReferenceString",
"deprecated": true
}
}
},
"initial_value": {},
"contract": {
"type": "object",
"properties": {
"raw": {
"type": "string"
},
},
"additionalProperties": false,
"required": ["raw"]
},
},
"required": [
"id",
"schema",
"initial_value",
"contract"
],
"additionalProperties": false
}
},
"policies": {
"type": "array",
"items": {
"type": "object",
"additionalProperties": false,
"required": [
"id", "approve", "evaluate", "validate"
],
"properties": {
"id": {
"type": "string"
},
"approve": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
},
"evaluate": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
},
"validate": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
}
}
}
}
}
}
Y su estado inicial es:
{
"members": [],
"roles": [
{
"namespace": "",
"role": "WITNESS",
"schema": {
"ID": "governance"
},
"who": "MEMBERS"
}
],
"schemas": [],
"policies": [
{
"id": "governance",
"approve": {
"quorum": "MAJORITY"
},
"evaluate": {
"quorum": "MAJORITY"
},
"validate": {
"quorum": "MAJORITY"
}
}
]
}
Esencialmente, el estado inicial de la gobernanza define que todos los miembros agregados a la gobernanza serán testigos, y se requiere una mayoría de firmas de todos los miembros para cualquiera de las fases del ciclo de vida de los eventos de cambio de gobernanza. Sin embargo, no tiene esquemas adicionales, estos deberán agregarse según las necesidades de los casos de uso.
El contrato de gobierno es:
mod sdk;
use std::collections::HashSet;
use thiserror::Error;
use sdk::ValueWrapper;
use serde::{de::Visitor, ser::SerializeMap, Deserialize, Serialize};
#[derive(Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum Who {
ID { ID: String },
NAME { NAME: String },
MEMBERS,
ALL,
NOT_MEMBERS,
}
impl Serialize for Who {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: serde::Serializer,
{
match self {
Who::ID { ID } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("ID", ID)?;
map.end()
}
Who::NAME { NAME } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("NAME", NAME)?;
map.end()
}
Who::MEMBERS => serializer.serialize_str("MEMBERS"),
Who::ALL => serializer.serialize_str("ALL"),
Who::NOT_MEMBERS => serializer.serialize_str("NOT_MEMBERS"),
}
}
}
impl<'de> Deserialize<'de> for Who {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
struct WhoVisitor;
impl<'de> Visitor<'de> for WhoVisitor {
type Value = Who;
fn expecting(&self, formatter: &mut std::fmt::Formatter) -> std::fmt::Result {
formatter.write_str("Who")
}
fn visit_map<A>(self, mut map: A) -> Result<Self::Value, A::Error>
where
A: serde::de::MapAccess<'de>,
{
// They should only have one entry
let Some(key) = map.next_key::<String>()? else {
return Err(serde::de::Error::missing_field("ID or NAME"))
};
let result = match key.as_str() {
"ID" => {
let id: String = map.next_value()?;
Who::ID { ID: id }
}
"NAME" => {
let name: String = map.next_value()?;
Who::NAME { NAME: name }
}
_ => return Err(serde::de::Error::unknown_field(&key, &["ID", "NAME"])),
};
let None = map.next_key::<String>()? else {
return Err(serde::de::Error::custom("Input data is not valid. The data contains unkown entries"));
};
Ok(result)
}
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v.as_str() {
"MEMBERS" => Ok(Who::MEMBERS),
"ALL" => Ok(Who::ALL),
"NOT_MEMBERS" => Ok(Who::NOT_MEMBERS),
other => Err(serde::de::Error::unknown_variant(
other,
&["MEMBERS", "ALL", "NOT_MEMBERS"],
)),
}
}
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v {
"MEMBERS" => Ok(Who::MEMBERS),
"ALL" => Ok(Who::ALL),
"NOT_MEMBERS" => Ok(Who::NOT_MEMBERS),
other => Err(serde::de::Error::unknown_variant(
other,
&["MEMBERS", "ALL", "NOT_MEMBERS"],
)),
}
}
}
deserializer.deserialize_any(WhoVisitor {})
}
}
#[derive(Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum SchemaEnum {
ID { ID: String },
NOT_GOVERNANCE,
ALL,
}
impl Serialize for SchemaEnum {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: serde::Serializer,
{
match self {
SchemaEnum::ID { ID } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("ID", ID)?;
map.end()
}
SchemaEnum::NOT_GOVERNANCE => serializer.serialize_str("NOT_GOVERNANCE"),
SchemaEnum::ALL => serializer.serialize_str("ALL"),
}
}
}
impl<'de> Deserialize<'de> for SchemaEnum {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
struct SchemaEnumVisitor;
impl<'de> Visitor<'de> for SchemaEnumVisitor {
type Value = SchemaEnum;
fn expecting(&self, formatter: &mut std::fmt::Formatter) -> std::fmt::Result {
formatter.write_str("Schema")
}
fn visit_map<A>(self, mut map: A) -> Result<Self::Value, A::Error>
where
A: serde::de::MapAccess<'de>,
{
// They should only have one entry
let Some(key) = map.next_key::<String>()? else {
return Err(serde::de::Error::missing_field("ID"))
};
let result = match key.as_str() {
"ID" => {
let id: String = map.next_value()?;
SchemaEnum::ID { ID: id }
}
_ => return Err(serde::de::Error::unknown_field(&key, &["ID", "NAME"])),
};
let None = map.next_key::<String>()? else {
return Err(serde::de::Error::custom("Input data is not valid. The data contains unkown entries"));
};
Ok(result)
}
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v.as_str() {
"ALL" => Ok(Self::Value::ALL),
"NOT_GOVERNANCE" => Ok(Self::Value::NOT_GOVERNANCE),
other => Err(serde::de::Error::unknown_variant(
other,
&["ALL", "NOT_GOVERNANCE"],
)),
}
}
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v {
"ALL" => Ok(Self::Value::ALL),
"NOT_GOVERNANCE" => Ok(Self::Value::NOT_GOVERNANCE),
other => Err(serde::de::Error::unknown_variant(
other,
&["ALL", "NOT_GOVERNANCE"],
)),
}
}
}
deserializer.deserialize_any(SchemaEnumVisitor {})
}
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Role {
who: Who,
namespace: String,
role: RoleEnum,
schema: SchemaEnum,
}
#[derive(Serialize, Deserialize, Clone)]
pub enum RoleEnum {
VALIDATOR,
CREATOR,
ISSUER,
WITNESS,
APPROVER,
EVALUATOR,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Member {
id: String,
name: String,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Contract {
raw: String,
}
#[derive(Serialize, Deserialize, Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum Quorum {
MAJORITY,
FIXED(u64),
PERCENTAGE(f64),
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Validation {
quorum: Quorum,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Policy {
id: String,
approve: Validation,
evaluate: Validation,
validate: Validation,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Schema {
id: String,
schema: serde_json::Value,
initial_value: serde_json::Value,
contract: Contract,
}
#[repr(C)]
#[derive(Serialize, Deserialize, Clone)]
pub struct Governance {
members: Vec<Member>,
roles: Vec<Role>,
schemas: Vec<Schema>,
policies: Vec<Policy>,
}
// Define "Event family".
#[derive(Serialize, Deserialize, Debug)]
pub enum GovernanceEvent {
Patch { data: ValueWrapper },
}
#[no_mangle]
pub unsafe fn main_function(state_ptr: i32, event_ptr: i32, is_owner: i32) -> u32 {
sdk::execute_contract(state_ptr, event_ptr, is_owner, contract_logic)
}
// Contract logic with expected data types
// Returns the pointer to the data written with the modified state.
fn contract_logic(
context: &sdk::Context<Governance, GovernanceEvent>,
contract_result: &mut sdk::ContractResult<Governance>,
) {
// It would be possible to add error handling
// It could be interesting to do the operations directly as serde_json:Value instead of "Custom Data".
let state = &mut contract_result.final_state;
let _is_owner = &context.is_owner;
match &context.event {
GovernanceEvent::Patch { data } => {
// A JSON PATCH is received
// It is applied directly to the state
let patched_state = sdk::apply_patch(data.0.clone(), &context.initial_state).unwrap();
if let Ok(_) = check_governance_state(&patched_state) {
*state = patched_state;
contract_result.success = true;
contract_result.approval_required = true;
} else {
contract_result.success = false;
}
}
}
}
#[derive(Error, Debug)]
enum StateError {
#[error("A member's name is duplicated")]
DuplicatedMemberName,
#[error("A member's ID is duplicated")]
DuplicatedMemberID,
#[error("A policy identifier is duplicated")]
DuplicatedPolicyID,
#[error("No governace policy detected")]
NoGvernancePolicy,
#[error("It is not allowed to specify a different schema for the governnace")]
GovernanceShchemaIDDetected,
#[error("Schema ID is does not have a policy")]
NoCorrelationSchemaPolicy,
#[error("There are policies not correlated to any schema")]
PoliciesWithoutSchema,
}
fn check_governance_state(state: &Governance) -> Result<(), StateError> {
// We must check several aspects of the status.
// There cannot be duplicate members, either in name or ID.
check_members(&state.members)?;
// There can be no duplicate policies and the one associated with the governance itself must be present.
let policies_names = check_policies(&state.policies)?;
// Schema policies that do not exist cannot be indicated. Likewise, there cannot be
// schemas without policies. The correlation must be one-to-one
check_schemas(&state.schemas, policies_names)
}
fn check_members(members: &Vec<Member>) -> Result<(), StateError> {
let mut name_set = HashSet::new();
let mut id_set = HashSet::new();
for member in members {
if name_set.contains(&member.name) {
return Err(StateError::DuplicatedMemberName);
}
name_set.insert(&member.name);
if id_set.contains(&member.id) {
return Err(StateError::DuplicatedMemberID);
}
id_set.insert(&member.id);
}
Ok(())
}
fn check_policies(policies: &Vec<Policy>) -> Result<HashSet<String>, StateError> {
// Check that there are no duplicate policies and that the governance policy is included.
let mut is_governance_present = false;
let mut id_set = HashSet::new();
for policy in policies {
if id_set.contains(&policy.id) {
return Err(StateError::DuplicatedPolicyID);
}
id_set.insert(&policy.id);
if &policy.id == "governance" {
is_governance_present = true
}
}
if !is_governance_present {
return Err(StateError::NoGvernancePolicy);
}
id_set.remove(&String::from("governance"));
Ok(id_set.into_iter().cloned().collect())
}
fn check_schemas(
schemas: &Vec<Schema>,
mut policies_names: HashSet<String>,
) -> Result<(), StateError> {
// We check that there are no duplicate schemas.
// We also have to check that the initial states are valid according to the json_schema
// Also, there cannot be a schema with id "governance".
for schema in schemas {
if &schema.id == "governance" {
return Err(StateError::GovernanceShchemaIDDetected);
}
// There can be no duplicates and they must be matched with policies_names
if !policies_names.remove(&schema.id) {
// Not related to policies_names
return Err(StateError::NoCorrelationSchemaPolicy);
}
}
if !policies_names.is_empty() {
return Err(StateError::PoliciesWithoutSchema);
}
Ok(())
}
Actualmente, el contrato de gobernanza está diseñado para admitir solo un método/evento: el “Patch”. Este método nos permite enviar cambios a la gobernanza en forma de JSON-Patch, un formato estándar para expresar una secuencia de operaciones para aplicar a un documento JavaScript Object Notation (JSON).
Por ejemplo, si tenemos una gobernanza predeterminada y queremos realizar un cambio, como agregar un miembro, primero calcularíamos el parche JSON para expresar este cambio. Esto se puede hacer usando cualquier herramienta que siga el estándar JSON Patch RFC 6902, o con el uso de nuestra propia herramienta, kore-patch.
De esta manera, el contrato de gobernanza aprovecha la flexibilidad del estándar JSON-Patch para permitir una amplia variedad de cambios de estado mientras mantiene una interfaz de método simple y única.
El contrato tiene una estrecha relación con el esquema, ya que tiene en cuenta su definición para obtener el estado antes de la ejecución del contrato y validarlo al final de dicha ejecución.
Actualmente, solo tiene una función que se puede llamar desde un evento de tipo Fact, el método Patch: Patch {data: ValueWrapper}. Este método obtiene un JSON patch que aplica los cambios que incluye directamente sobre las propiedades del sujeto de la gobernanza. Al final de su ejecución llama a la función que comprueba que el estado final obtenido tras aplicar el patch es una gobernanza válida.
3.2 - Contratos
Contratos en Kore Ledger.
3.2.1 - Contratos en Kore
Introducción a la programación de contratos en Kore Ledger.
Contratos y esquemas
En Kore, cada sujeto está asociado a un esquema que determina, fundamentalmente, sus propiedades. El valor de estas propiedades puede cambiar a lo largo del tiempo mediante la emisión de eventos, siendo necesario, en consecuencia, establecer el mecanismo a través del cual estos eventos realizan dicha acción. En la práctica, esto se gestiona a través de una serie de reglas que constituyen lo que llamamos un contrato.
En consecuencia, podemos decir que un esquema tiene siempre asociado un contrato que regula su evolución. La especificación de ambos se realiza en la gobernanza.
Entradas y salidas
Los contratos, aunque especificados en la gobernanza, sólo son ejecutados por aquellos nodos que tienen capacidades de evaluación y han sido definidos como tales en las reglas de gobernanza. Es importante señalar que Kore permite que un nodo actúe como evaluador de un sujeto incluso si no posee la cadena de eventos del sujeto, es decir, incluso si no es testigo. Esto ayuda a reducir la carga en estos nodos y contribuye al rendimiento general de la red.
Para lograr la correcta ejecución de un contrato, recibe tres entradas: el estado actual del sujeto, el evento a procesar y una flag que indica si la solicitud del evento ha sido emitida o no por el propietario del sujeto. Una vez recibidos estos insumos, el contrato debe utilizarlos para generar un nuevo estado válido. Tenga en cuenta que la lógica de esto último recae enteramente en el programador del contrato. El programador del contrato también determina qué eventos son válidos, es decir, decide la familia de eventos que se utilizará. Así, el contrato sólo aceptará eventos de esta familia, rechazando todos los demás, y que el programador pueda adaptar, en estructura y datos, a las necesidades de su caso de uso. Como ejemplo, supongamos un sujeto que representa el perfil de un usuario con su información de contacto así como su identidad; un evento de la familia podría ser aquel que solo actualice el número de teléfono del usuario. Por otro lado, la flag se puede utilizar para restringir ciertas operaciones únicamente al propietario del sujeto, ya que la ejecución del contrato se realiza tanto por los eventos que genera por sí mismo como por invocaciones externas.
Cuando un contrato termina de ejecutarse, genera tres resultados:
-
Flag de éxito: Mediante un booleano indica si la ejecución del contrato ha sido exitosa, es decir, si el evento debe provocar un cambio de estado del sujeto. Este indicador se establecerá en falso siempre que se produzca un error al obtener los datos de entrada del contrato o si la lógica del contrato así lo dicta. En otras palabras, se puede y se debe indicar explícitamente si la ejecución puede considerarse exitosa o no. Esto es importante porque estas decisiones dependen completamente del caso de uso, del cual Kore se abstrae en su totalidad. Así, por ejemplo, el programador podría determinar que si, tras la ejecución de un evento, el valor de una de las propiedades del sujeto ha superado un umbral, el evento no puede considerarse válido.
-
Estado final: Si el evento ha sido procesado exitosamente y la ejecución del contrato ha sido marcada como exitosa, entonces devuelve el nuevo estado generado, que en la práctica podría ser el mismo que el anterior. Este estado se validará con el esquema definido en la gobernanza para garantizar la integridad de la información. Si la validación no es exitosa, se cancela el indicador de éxito.
-
Flag de aprobación: el contrato debe decidir si un evento debe aprobarse o no. Nuevamente, esto dependerá enteramente del caso de uso, siendo responsabilidad del programador establecer cuándo es necesario. Así, la aprobación se fija como una fase facultativa pero también condicional.
ATENCIÓN
Los contratos Kore funcionan sin ningún estado asociado. Toda la información con la que pueden trabajar es la que reciben como entrada. Esto significa que el valor de las variables no se retiene entre ejecuciones, marcando una diferencia importante respecto a los contratos inteligentes de otras plataformas, como Ethereum.Ciclo de vida
Desarrollo
Los contratos se definen en proyectos locales de Rust, el único lenguaje permitido para escribirlos. Estos proyectos, que debemos definir como bibliotecas, deben importar el SDK de los contratos disponibles en los repositorios oficiales y, además, deben seguir las indicaciones especificadas en “cómo escribir un contrato”.
Distribución
Una vez definido el contrato, se debe incluir en una gobernanza y asociar a un esquema para que pueda ser utilizado por los nodos de una red. Para ello es necesario realizar una operación de actualización de gobernanza en la que se incluye el contrato en el apartado correspondiente y se codifica en base64. Si se ha definido una batería de prueba, no es necesario incluirla en el proceso de codificación.
ATENCIÓN
Dado que los nodos Kore están a cargo de la compilación del contrato, es necesario que la base64 incluya el contrato en su totalidad. En otras palabras, el contrato debe redactarse íntegramente en un único archivo y codificado.
Esta es una limitación actual y se espera que haya otras alternativas disponibles en el futuro.
Compilación
Si la solicitud de actualización tiene éxito, el estado de gobernanza cambiará y los nodos evaluadores compilarán el contrato como un módulo de Web Assembly, lo serializarán y lo almacenarán en su base de datos. Se trata de un proceso automatizado y autogestionado, por lo que no requiere la intervención del usuario en ninguna etapa del proceso.
Después de este paso, el contrato puede ser utilizado.
Ejecución
La ejecución del contrato se realizará en un Web Assembly Runtime, aislando su ejecución del resto del sistema. Esto evita el mal uso de sus recursos, añadiendo una capa de seguridad.
Rust y WASM
Web Assembly se utiliza para la ejecución de contratos debido a sus características:
- Alto rendimiento y eficiencia.
- Ofrece un entorno de ejecución aislado y seguro.
- Tiene una comunidad activa.
- Permite compilar desde varios lenguajes, muchos de ellos con una base de usuarios considerable.
- Los módulos resultantes de la compilación, una vez optimizados, son ligeros.
Se eligió Rust como lenguaje para escribir contratos de Kore debido a su capacidad de compilar en Web Assembly, así como a sus capacidades y especificaciones, la misma razón que motivó su elección para el desarrollo de Kore. Específicamente, Rust es un lenguaje centrado en escribir código seguro y de alto rendimiento, los cuales contribuyen a la calidad del módulo Web Assembly resultante. Además, el lenguaje cuenta de forma nativa con recursos para crear pruebas, lo que favorece la prueba de contratos.
3.2.2 - Programación de contratos
Cómo programar los contratos.
SDK
Para el correcto desarrollo de los contratos es necesario utilizar su SDK, proyecto que se puede encontrar en el repositorio oficial de Kore. El principal objetivo de este proyecto es abstraer al programador de la interacción con el contexto de la máquina evaluadora subyacente, haciendo mucho más fácil la obtención de los datos de entrada, así como el proceso de escritura del resultado del contrato.
El proyecto SDK se puede dividir en tres secciones. Por un lado, un conjunto de funciones cuya vinculación se produce en tiempo de ejecución y que tienen como objetivo poder interactuar con la máquina evaluadora, en particular, para leer y escribir datos en un buffer interno. Adicionalmente también distinguimos un módulo que, utilizando las funciones anteriores, se encarga de la serialización y deserialización de los datos, así como de proporcionar la función principal de cualquier contrato. Finalmente, destacamos una serie de funciones y estructuras de utilidad que se pueden utilizar activamente en el código.
Muchos de los elementos anteriores son privados, por lo que el usuario nunca tendrá la oportunidad de utilizarlos. Por ello, en esta documentación nos centraremos en aquellas que están expuestas al usuario y que éste podrá utilizar activamente en el desarrollo de sus contratos.
ATENCIÓN
Tenga en cuenta que no es posible ejecutar todas las funciones ni utilizar todos los tipos de datos en un entorno Web Assembly. Debes informarte sobre las posibilidades del entorno. Por ejemplo, se desactiva cualquier interacción con el sistema operativo, ya que es un entorno aislado y seguro.Estructuras auxiliares
#[derive(Serialize, Deserialize, Debug)]
pub struct Context<State, Event> {
pub initial_state: State,
pub event: Event,
pub is_owner: bool,
}
Esta estructura contiene los tres datos de entrada de cualquier contrato: el estado inicial o actual del sujeto, el evento entrante y una flag que indica si la persona que solicita el evento es o no el propietario del sujeto. Tenga en cuenta el uso de genéricos para el estado y el evento.
#[derive(Serialize, Deserialize, Debug)]
pub struct ContractResult<State> {
pub final_state: State,
pub approval_required: bool,
pub success: bool,
}
Contiene el resultado de la ejecución del contrato, siendo este una conjunción del estado resultante y dos flags que indican, por un lado, si la ejecución ha sido exitosa según los criterios establecidos por el programador (o si se ha producido en la carga de datos); y por otro lado, si el evento requiere aprobación o no.
pub fn execute_contract<F, State, Event>(
state_ptr: i32,
event_ptr: i32,
is_owner: i32,
callback: F,
) -> u32
where
State: for<'a> Deserialize<'a> + Serialize + Clone,
Event: for<'a> Deserialize<'a> + Serialize,
F: Fn(&Context<State, Event>, &mut ContractResult<State>);
Esta función es la función principal del SDK y, además, la más importante. En concreto se encarga de obtener los datos de entrada, datos que obtiene del contexto que comparte con la máquina evaluadora. La función, que inicialmente recibirá un puntero a cada uno de estos datos, se encargará de extraerlos del contexto y deserializarlos al estado y estructuras de eventos que espera recibir el contrato, los cuales pueden especificarse mediante genéricos. Estos datos, una vez obtenidos, se encapsulan en la estructura de contexto presente arriba y se pasan como argumentos a una función de devolución de llamada que gestiona la lógica del contrato, es decir, sabe qué hacer con los datos recibidos. Finalmente, independientemente de si la ejecución ha sido exitosa o no, la función se encargará de escribir el resultado en el contexto, para que pueda ser utilizado por la máquina evaluadora.
pub fn apply_patch<State: for<'a> Deserialize<'a> + Serialize>(
patch_arg: Value,
state: &State,
) -> Result<State, i32>;
Esta es la última característica pública del SDK y permite actualizar un estado aplicando un JSON-PATCH, útil en los casos en los que se considera que esta técnica actualiza el estado.
Tu primer contrato
Creando el proyecto
Localice la ruta y/o los directorios deseados y cree un nuevo paquete de carga utilizando cargo new NOMBRE --lib. El proyecto debería ser una biblioteca. Asegúrese de tener un archivo lib.rs y no un archivo main.rs.
Luego, incluye en el Cargo.toml como dependencia el SDK de los contratos y el resto de dependencias que quieras de la siguiente lista:
- serde.
- serde_json.
- json_patch.
- thiserror.
El Cargo.toml se debería contener algo como esto:
[package]
name = "kore_contract"
version = "0.1.0"
edition = "2021"
[dependencies]
serde = { version = "=1.0.198", features = ["derive"] }
serde_json = "=1.0.116"
json-patch = "=1.2"
thiserror = "=1.0"
# Note: Change the tag label to the appropriate one
kore-contract-sdk = { git = "https://github.com/kore-ledger/kore-contract-sdk.git", branch = "main"}
Escribiendo el contrato
El siguiente contrato no tiene una lógica complicada ya que ese aspecto depende de las necesidades del propio contrato, pero sí que contiene un amplio abanico de los tipos que se pueden usar y cómo se deben usar. Dado que la compilación la realizará el nodo, debemos escribir el contrato completo en el archivo lib.rs.
En nuestro caso, iniciaremos el contrato especificando los paquetes que vamos a utilizar.
use kore_contract_sdk as sdk;
use serde::{Deserialize, Serialize};
A continuación, es necesario especificar la estructura de datos que representará el estado de nuestros sujetos así como la familia de eventos que recibiremos.
#[derive(Serialize, Deserialize, Clone)]
struct State {
pub text: String,
pub value: u32,
pub array: Vec<String>,
pub boolean: bool,
pub object: Object,
}
#[derive(Serialize, Deserialize, Clone)]
struct Object {
number: f32,
optional: Option<i32>,
}
#[derive(Serialize, Deserialize)]
enum StateEvent {
ChangeObject {
obj: Object,
},
ChangeOptional {
integer: i32,
},
ChangeAll {
text: String,
value: u32,
array: Vec<String>,
boolean: bool,
object: Object,
},
}
INFORMACIÓN
La familia de eventos se definirá generalmente como un enumerado, aunque en la práctica nada impide que sea una estructura si es necesario. En cualquier caso, si se utiliza un enumerado, si sus variantes reciben datos, éstos deberán especificarse mediante una estructura anónima y no mediante la sintaxis de tuplas.
También hay que tener en cuenta que los eventos de la familia pueden ser subconjuntos de los eventos reales. Así, por ejemplo, el contrato aceptaría un evento StateEvent::ChangeObject que incluya más datos que el atributo obj. El contrato, cuando se ejecute, sólo conservará los datos necesarios, descartando todos los demás datos en el proceso de deserialización. Esto podría utilizarse para almacenar información en la cadena que no es necesaria para la lógica del contrato.
ATENCIÓN
Nótese que la implementación del traitSerialize y Deserialize son obligatorias para especificar el estado y los eventos. Además, el primero también debe implementar Clone.
A continuación definimos la función de entrada al contrato, el equivalente a la función main. Es importante que esta función tenga siempre el mismo nombre que el especificado aquí, ya que es el identificador con el que la máquina evaluadora intentará ejecutarla, produciendo un error si no se encuentra.
#[no_mangle]
pub unsafe fn main_function(state_ptr: i32, event_ptr: i32, is_owner: i32) -> u32 {
sdk::execute_contract(state_ptr, event_ptr, is_owner, contract_logic)
}
Esta función debe ir siempre acompañada del atributo #[no_mangle] y sus parámetros de entrada y salida deben coincidir también con los del ejemplo. En concreto, esta función recibirá los punteros a los datos de entrada, que serán procesados por la función SDK. Como salida, se generará un nuevo puntero al resultado del contrato que, como se ha mencionado anteriormente, es obtenido por el SDK y no por el programador.
INFORMACIÓN
La modificación de los valores de los punteros en esta sección del código no tendrá ningún efecto. Los punteros son con respecto al contexto compartido, que corresponde a un único buffer por ejecución de contrato. Alterar los valores de los punteros no permite al programador acceder a información arbitraria ni de la máquina evaluadora ni de otros contratos.Por último, especificamos la lógica de nuestro contrato, que puede estar definida por tantas funciones como deseemos. Preferiblemente se destacará una función principal, que será la que ejecutará como callback la función execute_contract del SDK.
fn contract_logic(
context: &sdk::Context<State, StateEvent>,
contract_result: &mut sdk::ContractResult<State>,
) {
let state = &mut contract_result.final_state;
match &context.event {
StateEvent::ChangeObject { obj } => {
state.object = obj.to_owned();
}
StateEvent::ChangeOptional { integer } => state.object.optional = Some(*integer),
StateEvent::ChangeAll {
text,
value,
array,
boolean,
object,
} => {
state.text = text.to_string();
state.value = *value;
state.array = array.to_vec();
state.boolean = *boolean;
state.object = object.to_owned();
}
}
contract_result.success = true;
contract_result.approval_required = true;
}
Esta función principal recibe los datos de entrada del contrato encapsulados en una instancia de la estructura Context del SDK. También recibe una referencia mutable al resultado del contrato que contiene el estado final, originalmente idéntico al estado inicial, y las flags de aprobación requerida y ejecución correcta, contract_result.approval_required y contract_result.success, respectivamente. Nótese cómo, además de modificar el estado en función del evento recibido, hay que modificar las flags anteriores. Con la primera especificaremos que el contrato acepta el evento y los cambios que propone para el estado actual del sujeto, lo que se traducirá en el SDK generando un JSON_PATCH con las modificaciones necesarias para transitar del estado inicial al obtenido. La segunda flag, por su parte, nos permite indicar condicionalmente si consideramos que el evento debe ser aprobado o no.
Testeando el contrato
Al ser código Rust, podemos crear una batería de pruebas unitarias en el propio código del contrato para comprobar su rendimiento utilizando los recursos del propio lenguaje. También sería posible especificarlos en un archivo diferente.
// Testing Change Object
#[test]
fn contract_test_change_object() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeObject {
obj: Object {
number: 21.70,
optional: Some(64),
},
},
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(result.final_state.object.number, 21.70);
assert_eq!(result.final_state.object.optional, Some(64));
assert!(result.success);
assert!(result.approval_required);
}
// Testing Change Optional
#[test]
fn contract_test_change_optional() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
// Testing Change Object
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeOptional { integer: 1000 },
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(result.final_state.object.optional, Some(1000));
assert_eq!(result.final_state.object.number, 0.5);
assert!(result.success);
assert!(result.approval_required);
}
// Testing Change All
#[test]
fn contract_test_change_all() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
// Testing Change Object
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeAll {
text: "Kore_contract_test_all".to_string(),
value: 2024,
array: vec!["Kore".to_string(), "Ledger".to_string(), "SL".to_string()],
boolean: true,
object: Object {
number: 0.005,
optional: Some(2024),
},
},
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(
result.final_state.text,
"Kore_contract_test_all".to_string()
);
assert_eq!(result.final_state.value, 2024);
assert_eq!(
result.final_state.array,
vec!["Kore".to_string(), "Ledger".to_string(), "SL".to_string()]
);
assert_eq!(result.final_state.boolean, true);
assert_eq!(result.final_state.object.optional, Some(2024));
assert_eq!(result.final_state.object.number, 0.005);
assert!(result.success);
assert!(result.approval_required);
}
Como puede ver, lo único que necesita hacer para crear una prueba válida es definir manualmente un estado inicial y un evento entrante en lugar de utilizar la función ejecutora del SDK, que sólo puede ser ejecutada correctamente por Kore. Una vez definidas las entradas, hacer una llamada a la función principal de la lógica del contrato debería ser suficiente.
Una vez probado el contrato, está listo para ser enviado a Kore como se indica en la sección de introducción. Tenga en cuenta que no es necesario enviar las pruebas del contrato a los nodos Kore. De hecho, enviarlas supondrá un mayor uso de bytes del fichero codificado y, en consecuencia, al estar almacenado en el gobierno, un mayor consumo de bytes del mismo.
3.3 - Aprende JSON Schema
Especificación y ejemplos de JSON Schema.
El JSON Schema especificación está en estado BORRADOR en el IETF, sin embargo, se utiliza ampliamente en la actualidad y prácticamente se considera un estándar de facto.
JSON Schema establece un conjunto de reglas que modelan y validan una estructura de datos. El siguiente ejemplo define un esquema que modela una estructura de datos simple con 2 campos: id y value. También se indica que el id es obligatorio y que no se permiten campos adicionales.
{
"type": "object",
"additionalProperties": false,
"required": [
"id"
],
"properties": {
"id": {"type":"string"},
"value": {"type":"integer"}
}
}
JSON OBJECT CORRECTO
{
"id": "id_1",
"value": 23
}
JSON OBJECTS INCORRECTOS
{
"value": 3 // id no está definida y es obligatoria
}
{
"id": "id_3",
"value": 3,
"count": 5 // no se permiten propiedades adicionales
}
JSON SCHEMA ONLINE VALIDATOR
Puede probar este comportamiento utilizando este validador de JSON Schema interactivo y en línea.Creando un JSON Schema
El siguiente ejemplo no es de ninguna manera definitivo de todo el valor que puede proporcionar el JSON Schema. Para ello necesitarás profundizar en la propia especificación. Obtenga más información en especificación del JSON Schema.
Supongamos que estamos interactuando con el registro de un automóvil basado en JSON. Esta matrícula tiene un coche que tiene:
- Un identificador del fabricante:
chassisNumber - Identificación del país de registro:
licensePlate - Número de kilómetros recorridos:
mileage - Un conjunto opcional de etiquetas:
tags.
Por ejemplo
{
"chassisNumber": 72837362,
"licensePlate": "8256HYN",
"mileage": 60000,
"tags": [ "semi-new", "red" ]
}
Si bien en general es sencillo, el ejemplo deja algunas preguntas abiertas. Éstos son sólo algunos de ellos:
- ¿Qué es
chassisNumber? - ¿Se requiere
licensePlate? - ¿El
mileagepuede ser menor que cero? - ¿Todas las
tagsson valores de cadena?
Cuando habla de un formato de datos, desea tener metadatos sobre el significado de las claves, incluidas las entradas válidas para esas claves. JSON Schema es un estándar propuesto por el IETF sobre cómo responder esas preguntas sobre datos.
Iniciando el esquema
Para iniciar una definición de esquema, comencemos con un JSON Schema básico.
Comenzamos con cuatro propiedades llamadas palabras clave que se expresan como claves JSON.
Sí. el estándar utiliza un documento de datos JSON para describir documentos de datos, que en la mayoría de los casos también son documentos de datos JSON, pero que pueden estar en cualquier otro tipo de contenido como
text/xml.
- La palabra clave
$schemaindica que este esquema está escrito de acuerdo con un código específico. - La palabra clave
$iddefine un Identificador de recursos uniforme(URI) para el esquema y la base URI con el que se resuelven otras referencias de URI dentro del esquema. - El
titley ladescriptionlas palabras clave de anotación son solo descriptivas. No añaden restricciones a los datos que se validan. La intención del esquema se expresa con estas dos palabras clave. - La palabra clave de validación
typedefine la primera restricción en nuestros datos JSON y en este caso tiene que ser un JSON Object.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object"
}
Introducimos las siguientes piezas de terminología cuando iniciamos el esquema:
- Schema Keyword:
$schemaand$id. - Schema Annotations:
titleanddescription. - Validation Keyword:
type.
Definiendo las propiedades
chassisNumber es un valor numérico que identifica de forma única un automóvil. Dado que este es el identificador canónico de una variable, no tiene sentido tener un automóvil sin uno, por lo que es obligatorio.
En términos de JSON Schema, actualizamos nuestro esquema para agregar:
- La palabra clave de validación
properties. - La clave
chassisNumber.- Se anotan las claves del esquema
descriptiony la palabra clave de validacióntype; cubrimos ambas en la sección anterior.
- Se anotan las claves del esquema
- La lista de palabras clave de validación
requiredchassisNumber.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
}
},
"required": [ "chassisNumber" ]
}
licensePlatees un valor de cadena que actúa como identificador secundario. Como no hay ningún coche sin matrícula, también es obligatorio.- Dado que la palabra clave de validación
requiredes un array destrings, podemos anotar varias claves según sea necesario; Ahora incluimoslicensePlate.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
}
},
"required": [ "chassisNumber", "licensePlate" ]
}
Profundizando con las propiedades
Según el registro de coches, no pueden tener mileage negativo.
- La clave
mileagese agrega con la anotación de esquemadescriptionhabitual y las palabras clave de validación detypecubiertas anteriormente. También se incluye en el array de claves definida por la palabra clave de validaciónrequired. - Especificamos que el valor de
mileagedebe ser mayor o igual a cero usando elminimumpalabra clave de validación.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
A continuación, llegamos a la clave tags.
El registro de vehículos ha establecido lo siguiente:
- Si hay
tagsdebe haber al menos una etiqueta, - Todas las
tagsdeben ser únicas; no hay duplicación dentro de un solo automóvil. - Todas las
tagsdeben ser de texto. - Las
tagsson bonitas pero no es necesario que estén presentes.
Por lo tanto:
- La clave
tagsse agrega con las anotaciones y palabras clave habituales. - Esta vez la palabra clave de validación
typeesarray. - Introducimos la palabra clave de validación
itemspara que podamos definir lo que aparece en el formación. En este caso: valores destringa través de la palabra clave de validacióntype. - La palabra clave de validación
minItemsse utiliza para garantizar que haya al menos una elemento en el array. - La palabra clave de validación
uniqueItemsindica que todos los elementos del array deben ser únicos entre sí. - No agregamos esta clave al array de palabras clave de validación
requiredporque es opcional.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
},
"tags": {
"description": "Tags for the car",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
Anidar estructuras de datos
Hasta este punto hemos estado tratando con un esquema muy plano: sólo un nivel. Esta sección demuestra estructuras de datos anidadas.
- La clave
dimensionsse agrega usando los conceptos que hemos descubierto anteriormente. Dado que la palabra clave de validacióntypeesobject, podemos usar la palabra clave de validaciónpropertiespara definir una estructura de datos anidada.- Omitimos la palabra clave de anotación
descriptionpor motivos de brevedad en el ejemplo. Si bien normalmente es preferible realizar anotaciones exhaustivas, en este caso la estructura y los nombres de las claves son bastante familiares para la mayoría de los desarrolladores.
- Omitimos la palabra clave de anotación
- Notará que el alcance de la palabra clave de validación
requiredse aplica a la clave de dimensiones y no más allá.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
},
"tags": {
"description": "Tags for the car",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
},
"dimensions": {
"type": "object",
"properties": {
"length": {
"type": "number"
},
"width": {
"type": "number"
},
"height": {
"type": "number"
}
},
"required": [ "length", "width", "height" ]
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
Echando un vistazo a los datos de nuestro JSON Schema
Ciertamente hemos ampliado el concepto de automóvil desde nuestros primeros datos de muestra (desplácese hacia arriba). Echemos un vistazo a los datos que coinciden con el JSON Schema que hemos definido.
{
"chassisNumber": 1,
"licensePlate": "8256HYN",
"mileage": 60000,
"tags": [ "semi-new", "red" ],
"dimensions": {
"length": 4.005,
"width": 1.932,
"height": 1.425
}
}
INFORMACIÓN
Este tutorial se basa en el tutorial de JSON Schema “Cómo comenzar paso a paso”. Si desea obtener más información sobre JSON Schema, visite el sitio web de JSON-Schema para obtener el tutorial original y otros recursos.3.4 - Kore Base
Documentación de Kore Base.
3.4.1 - Arquitectura
Arquitectura de Kore Base.
Kore Base es una biblioteca que implementa la mayor parte de la funcionalidad de los protocolos Kore. La forma más directa de desarrollar una aplicación compatible con Kore es utilizar esta biblioteca como hace, por ejemplo, Kore Client.
Internamente, está estructurada en una serie de capas con diferentes responsabilidades. A continuación se muestra una vista simplificada a nivel de capas y bloques de la estructura de Kore Base.
Red
Capa encargada de gestionar las comunicaciones en red, es decir, el envío y recepción de información entre los diferentes nodos de la red. Internamente, la implementación se basa en el uso de LibP2P para resolver las comunicaciones punto a punto. Para ello, se utilizan los siguientes protocolos:
- Kademlia, tabla hash distribuida utilizada como base de la funcionalidad de enrutamiento entre pares.
- Identify, protocolo que permite a los pares intercambiar información sobre los demás, especialmente sus claves públicas y direcciones de red conocidas.
- Noise, esquema de cifrado que permite una comunicación segura combinando primitivas criptográficas en patrones con propiedades de seguridad verificables.
- Tell, protocolo asíncrono de envío de mensajes. Tell surgió dentro del desarrollo de Kore como alternativa al protocolo LibP2P Request Response que requería esperar respuestas.
Mensajes
Capa encargada de gestionar las tareas de envío de mensajes. El protocolo de comunicaciones Kore gestiona diferentes tipos de mensajes. Algunos de ellos requieren una respuesta. Dado que las comunicaciones son asíncronas, no se espera una respuesta inmediata. Por ello, algunos tipos de mensajes deben reenviarse periódicamente hasta que se cumplan las condiciones necesarias. Esta capa se encarga de encapsular los mensajes de protocolo y gestionar las tareas de reenvío.
Protocolo
Capa encargada de gestionar los diferentes tipos de mensajes del protocolo Kore y redirigirlos a las partes de la aplicación encargadas de gestionar cada tipo de mensaje.
Ledger
Capa encargada de gestionar las cadenas de eventos, los microledgers. Esta capa se encarga de la gestión de sujetos, eventos, actualizaciones de estado, actualización de cadenas obsoletas, etc.
Gobernanza
Módulo que gestiona las gobernanzas. Diferentes partes de la aplicación necesitan resolver condiciones sobre el estado actual o pasado de alguna de las gobernaciones en las que participa. Este módulo se encarga de gestionar estas operaciones.
API
Capa encargada de exponer la funcionalidad del nodo Kore. Consultas de asuntos y eventos, emisión de solicitudes o gestión de aprobaciones son algunas de las funcionalidades expuestas. También se expone un canal de notificaciones en el que se publican los diferentes eventos que ocurren dentro del nodo, como por ejemplo la creación de materias o eventos.
3.4.2 - FFI
Implementación de FFI.
Kore ha sido diseñado con la intención de que pueda ser construido y ejecutado en diferentes arquitecturas, dispositivos, e incluso desde lenguajes distintos a Rust.
La mayor parte de la funcionalidad de Kore se ha implementado en una librería, Kore Base. Sin embargo, esta librería por sí sola no permite ejecutar un nodo Kore ya que, por ejemplo, necesita la implementación de una base de datos. Esta base de datos debe ser proporcionada por el software que integra la librería Kore Base. Por ejemplo, Kore Client integra una base de datos LevelDB.
Sin embargo, para ejecutar Kore en otras arquitecturas o lenguajes necesitamos una serie de elementos adicionales:
- Exponer una Foreign Function Interface (FFI) que permita interactuar con la librería Kore desde otros lenguajes.
- Vinculaciones al lenguaje de destino. Facilitar la interacción con la librería.
- Capacidad de compilación cruzada a la arquitectura de destino.
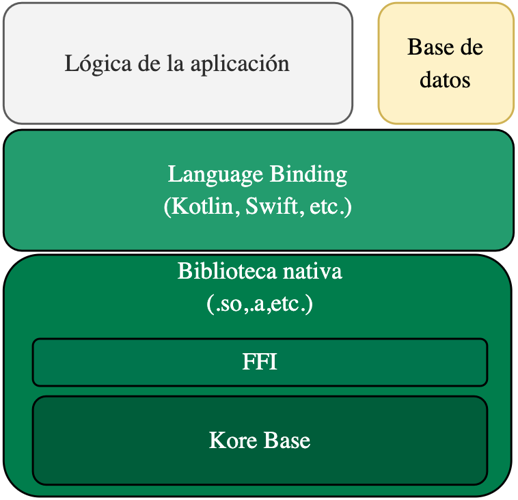
INFO
Explore los repositorios Kore relacionados con FFI para obtener más información.3.5 - Kore Node
Intermediario entre los diferentes Kore Clients y Kore Base.
3.5.1 - Qué es
¿Qué es Kore Node?.
Kore Node es in intermediario entre Kore Base y los diferentes Kore Clients como podría ser Kore HTTP. Sus principales funciones son 4:
- Crear una API que consumiran los diferentes Kore Clients para poder comunicarse con Kore Base, el objetivo de esta API es la simplificación de los tipos, es decir, se encarga de recibir tipos básicos como
Stringy convertirlos en tipos complejos que espera recibir Kore Base como unDigestIdentifier. Otro objetivo de esta API es convinar diferentes métodos de la API de Kore Base para realizar una funcionalidad concreta como podría ser la de crear un sujeto de trazabilidad, de esta forma añadimos una capa de abstracción sobre la API de Kore Base. - Implementar los diferentes métodos que necesitan las bases de datos para que Kore Base pueda utilizarlas, de esta forma Kore Base no está acoplado con ninguna base de datos y definiendo unos métodos es capaz de funcionar con un LevelDB, un SQlite o un Cassandra.
- Recibir los parámetros de configuración a través de archivos
.toml,.yamly.json; además devariables de entorno. Para profundizar sobre los parámetros de configuración visite la siguiente sección. - Exponer un Prometheus de forma opcional para poder obtener métricas. Para obtener más información sobre la configuración del prometheus visite la siguiente sección.
Acutalmente Kore Node consta de 3 features:
- sqlite: Para hacer uso de la base de datos de
SQlite. - leveldb: Para hacer uso de la base de datos de
LevelDB. - prometheus: para exponer una API con un
endpointllamado/metricsdonde se podrán obtener métricas.
INFO
Para acceder a más información sobre el funcionamiento de Kore Node, acceda al repositorio.3.5.2 - Configuración
Configuración de Kore Node
Estos parámetros de configuración son generales a cualquier nodo indpendientemente del tipo de cliente que se vaya a usar, los parámetros específicos de cada cliente se encontrarán en sus respectivas secciones.
La configuración de un nodo puede realizarse de diferentes maneras. A continuación se enumeran los mecanismos admitidos, de menor a mayor prioridad:
- Variables de entorno.
- Archivo de configuración.
Variables de entorno
Los siguientes parámetros de configuración solo se pueden configurar a través de variables de entorno y como parámetros al binario que se genera al compilar el cliente, pero no haciendo uso de archivos:
| Variable de entorno | Descripción | Parámetro de entrada | Qué recibe |
KORE_PASSWORD |
Contraseña que se utilizará para encriptar el material criptográfico | -p |
La contraseña |
KORE_FILE_PATH |
Ruta del archivo de configuración a utilizar | -f |
Ruta del archivo |
Los parámetros que se pueden configurar mediante variables de entorno y archivos son:
| Variable de entorno | Descripción | Qué recibe | Valor por defecto |
KORE_PROMETHEUS |
Dirección y puerto donde se va a exponer el servidor que contiene el endpoint /metrics donde se encuentra el prometheus |
Una dirección IP y un puerto | 0.0.0.0:3050 |
KORE_KEYS_PATH |
Ruta donde se guardará la clave privada en formato PKCS8 encriptada con PKCS5 |
Un directorio | examples/keys |
KORE_DB_PATH |
Ruta donde se creará la base de datos si no existe o donde se encuentra la base de datos en caso de que ya exista | Un directorio | Para LevelDB examples/leveldb y para SQlite examples/sqlitedb |
KORE_NODE_KEY_DERIVATOR |
Key derivator a utilizar |
Un String con Ed25519 o Secp256k1 |
Ed25519 |
KORE_NODE_DIGEST_DERIVATOR |
Digest derivator a utilizar |
Un String con Blake3_256, Blake3_512, SHA2_256, SHA2_512, SHA3_256 o SHA3_512 |
Blake3_256 |
KORE_NODE_REPLICATION_FACTOR |
Porcentaje de nodos de red que reciben mensajes de protocolo en una iteración | Valor flotante | 0.25 |
KORE_NODE_TIMEOUT |
Tiempo de espera que se utilizará entre iteraciones del protocolo | Valor entero sin signo | 3000 |
KORE_NODE_PASSVOTATION |
Comportamiento del nodo en la fase de aprobación | Valor entero sin signo, 1 para aprobar siempre, 2 para denegar siempre, otro valor para aprobación manual | 0 |
KORE_NODE_SMARTCONTRACTS_DIRECTORY |
Directorio donde se almacenarán los contratos de los sujetos | Un directorio | Contracts |
KORE_NETWORK_PORT_REUSE |
Verdadero para configurar la reutilización de puertos para sockets locales, lo que implica la reutilización de puertos de escucha para conexiones salientes para mejorar las capacidades transversales de NAT. | Valor Boolean | false |
KORE_NETWORK_USER_AGENT |
El user agent | El user agent | kore-node |
KORE_NETWORK_NODE_TYPE |
Tipo de nodo | Un String: Bootstrap, Addressable o Ephemeral | Bootstrap |
KORE_NETWORK_LISTEN_ADDRESSES |
Direcciones donde el nodo va a escuchar | Direcciones donde el nodo va a escuchar | /ip4/0.0.0.0/tcp/50000 |
KORE_NETWORK_EXTERNAL_ADDRESSES |
Dirección externa por la cual se puede acceder al nodo, pero no se encuentra entre sus interfaces | Dirección externa por la cual se puede acceder al nodo, pero no se encuentra entre sus interfaces | /ip4/90.0.0.70/tcp/50000 |
KORE_NETWORK_ROUTING_BOOT_NODES |
Direcciones de los Boot Nodes en la red P2P a los cuales nos conectaremos para empezar a formar parte de la red | Direcciones de los Boot Nodes, donde si tiene más de una dirección será separada con una _ y las direcciones se separan del Peer-ID del nodo mediante /p2p/ |
|
KORE_NETWORK_ROUTING_DHT_RANDOM_WALK |
Verdadero para activar el random walk en la DHT de Kademlia |
Valor Boolean | true |
KORE_NETWORK_ROUTING_DISCOVERY_ONLY_IF_UNDER_NUM |
Número de conexiones activas sobre las que interrumpimos el proceso de descubrimiento | Cantidad de conexiónes activas | u64::MAX |
KORE_NETWORK_ROUTING_ALLOW_NON_GLOBALS_IN_DHT |
Verdadero si se permiten direcciones no globales en el DHT | Valor Boolean | false |
KORE_NETWORK_ROUTING_ALLOW_PRIVATE_IP |
Si es false el dirección de un nodo no puede ser privada | Valor Boolean | false |
KORE_NETWORK_ROUTING_ENABLE_MDNS |
Verdadero para activar mDNS | Valor Boolean | true |
KORE_NETWORK_ROUTING_KADEMLIA_DISJOINT_QUERY_PATHS |
Cuando está habilitado, el número de rutas separadas utilizadas es igual al paralelismo configurado | Valor Boolean | true |
KORE_NETWORK_ROUTING_KADEMLIA_REPLICATION_FACTOR |
El factor de replicación determina a cuántos peers más cercanos se replica un registro | Valor entero sin signo mayor a 0 | false |
KORE_NETWORK_ROUTING_PROTOCOL_NAMES |
Protocolos que soporta el nodo | Protocolos que soporta el nodo | /kore/routing/1.0.0 |
KORE_NETWORK_TELL_MESSAGE_TIMEOUT_SECS |
Tiempo de espera de un mensaje | Cantidad de segundos | 10 |
KORE_NETWORK_TELL_MAX_CONCURRENT_STREAMS |
Cantidad máxima de transmisiones simultáneas | Valor entero sin signo | 100 |
KORE_NETWORK_CONTROL_LIST_ENABLE |
Habilitar lista de control | Valor booleano | true |
KORE_NETWORK_CONTROL_LIST_ALLOW_LIST |
Lista de peers permitidos | Cadena de texto separada por comas | Peer200,Peer300 |
KORE_NETWORK_CONTROL_LIST_BLOCK_LIST |
Lista de peers bloqueados | Cadena de texto separada por comas | Peer1,Peer2 |
KORE_NETWORK_CONTROL_LIST_SERVICE_ALLOW_LIST |
Lista de URLs de servicios permitidos | Cadena de texto separada por comas | http://90.0.0.1:3000/allow_list |
KORE_NETWORK_CONTROL_LIST_SERVICE_BLOCK_LIST |
Lista de URLs de servicios bloqueados | Cadena de texto separada por comas | http://90.0.0.1:3000/block_list |
KORE_NETWORK_CONTROL_LIST_INTERVAL_REQUEST |
Intervalo de solicitud en segundos | Cantidad de segundos | 58 |
.json File
{
"kore": {
"network": {
"user_agent": "Kore2.0",
"node_type": "Addressable",
"listen_addresses": ["/ip4/127.0.0.1/tcp/50000","/ip4/127.0.0.1/tcp/50001","/ip4/127.0.0.1/tcp/50002"],
"external_addresses": ["/ip4/90.1.0.60/tcp/50000", "/ip4/90.1.0.61/tcp/50000"],
"tell": {
"message_timeout_secs": 58,
"max_concurrent_streams": 166
},
"control_list": {
"enable": true,
"allow_list": ["Peer200", "Peer300"],
"block_list": ["Peer1", "Peer2"],
"service_allow_list": ["http://90.0.0.1:3000/allow_list", "http://90.0.0.2:4000/allow_list"],
"service_block_list": ["http://90.0.0.1:3000/block_list", "http://90.0.0.2:4000/block_list"],
"interval_request": 99
},
"routing": {
"boot_nodes": ["/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B","/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"],
"dht_random_walk": false,
"discovery_only_if_under_num": 55,
"allow_non_globals_in_dht": true,
"allow_private_ip": true,
"enable_mdns": false,
"kademlia_disjoint_query_paths": false,
"kademlia_replication_factor": 30,
"protocol_names": ["/kore/routing/2.2.2","/kore/routing/1.1.1"]
},
"port_reuse": true
},
"node": {
"key_derivator": "Secp256k1",
"digest_derivator": "Blake3_512",
"replication_factor": 0.555,
"timeout": 30,
"passvotation": 50,
"smartcontracts_directory": "./fake_route"
},
"db_path": "./fake/db/path",
"keys_path": "./fake/keys/path",
"prometheus": "10.0.0.0:3030"
}
}
.toml File
[kore.network]
user_agent = "Kore2.0"
node_type = "Addressable"
port_reuse = true
listen_addresses = ["/ip4/127.0.0.1/tcp/50000","/ip4/127.0.0.1/tcp/50001","/ip4/127.0.0.1/tcp/50002"]
external_addresses = ["/ip4/90.1.0.60/tcp/50000","/ip4/90.1.0.61/tcp/50000"]
[kore.network.control_list]
enable = true
allow_list = ["Peer200", "Peer300"]
block_list = ["Peer1", "Peer2"]
service_allow_list = ["http://90.0.0.1:3000/allow_list", "http://90.0.0.2:4000/allow_list"]
service_block_list = ["http://90.0.0.1:3000/block_list", "http://90.0.0.2:4000/block_list"]
interval_request = 99
[kore.network.tell]
message_timeout_secs = 58
max_concurrent_streams = 166
[kore.network.routing]
boot_nodes = ["/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B", "/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"]
dht_random_walk = false
discovery_only_if_under_num = 55
allow_non_globals_in_dht = true
allow_private_ip = true
enable_mdns = false
kademlia_disjoint_query_paths = false
kademlia_replication_factor = 30
protocol_names = ["/kore/routing/2.2.2", "/kore/routing/1.1.1"]
[kore.node]
key_derivator = "Secp256k1"
digest_derivator = "Blake3_512"
replication_factor = 0.555
timeout = 30
passvotation = 50
smartcontracts_directory = "./fake_route"
[kore]
db_path = "./fake/db/path"
keys_path = "./fake/keys/path"
prometheus = "10.0.0.0:3030"
.yaml File
kore:
network:
control_list:
allow_list:
- "Peer200"
- "Peer300"
block_list:
- "Peer1"
- "Peer2"
service_allow_list:
- "http://90.0.0.1:3000/allow_list"
- "http://90.0.0.2:4000/allow_list"
service_block_list:
- "http://90.0.0.1:3000/block_list"
- "http://90.0.0.2:4000/block_list"
interval_request: 99
enable: true
user_agent: "Kore2.0"
node_type: "Addressable"
listen_addresses:
- "/ip4/127.0.0.1/tcp/50000"
- "/ip4/127.0.0.1/tcp/50001"
- "/ip4/127.0.0.1/tcp/50002"
external_addresses:
- "/ip4/90.1.0.60/tcp/50000"
- "/ip4/90.1.0.61/tcp/50000"
tell:
message_timeout_secs: 58
max_concurrent_streams: 166
routing:
boot_nodes:
- "/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B"
- "/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"
dht_random_walk: false
discovery_only_if_under_num: 55
allow_non_globals_in_dht: true
allow_private_ip: true
enable_mdns: false
kademlia_disjoint_query_paths: false
kademlia_replication_factor: 30
protocol_names:
- "/kore/routing/2.2.2"
- "/kore/routing/1.1.1"
port_reuse: true
node:
key_derivator: "Secp256k1"
digest_derivator: "Blake3_512"
replication_factor: 0.555
timeout: 30
passvotation: 50
smartcontracts_directory: "./fake_route"
db_path: "./fake/db/path"
keys_path: "./fake/keys/path"
prometheus: "10.0.0.0:3030"
3.6 - Kore Clients
Types of clients.
3.6.1 - Kore HTTP
Cliente HTTP de Kore Base.
Es un cliente de kore base que utiliza el protocolo HTTP, permite interactuar mediante una api con los nodos Kore Ledger. Si desea acceder a información sobre la Api.
Dispone de una única variable de configuración que solo se obtiene por variable de entorno.
| Variable de entorno | Descripción | Qué recibe | Valores por defecto |
KORE_HTTP_ADDRESS |
Dirección donde podremos acceder a la api | Dirección ip y puerto | 0.0.0.0:3000 |
INFO
Para acceder a más información sobre cómo funciona Kore HTTP, dispone del repositorio además, una vez que el nodo esté levantado si se accede en la ruta/doc, se puede interactuar a través de la interfaz de rapidoc.
3.6.2 - Kore Modbus
Cliente Modbus de Kore Base.
Proximamente
3.7 - Herramientas
Utilidades para trabajar con Kore Node
Kore Tools son un grupo de utilidades desarrolladas para facilitar el uso de Kore Node, especialmente durante las pruebas y la creación de prototipos. En este apartado profundizaremos en ellos y en cómo se pueden obtener y utilizar.
Instalación
Existen diferentes formas en las que el usuario puede adquirir estas herramientas. La primera y más básica es la generación de sus binarios mediante la compilación de su código fuente, el cual se puede obtener a través de los repositorios públicos. Sin embargo, recomendamos hacer uso de las imágenes de Docker disponibles junto con una serie de scripts que abstraen el uso de estas imágenes, de modo que el usuario no necesite compilar el código.
Compilando binarios
$ git clone git@github.com:kore-ledger/kore-tools.git
$ cd kore-tools
$ sudo apt install -y libprotobuf-dev protobuf-compiler cmake
$ cargo install --locked --path keygen
$ cargo install --locked --path patch
$ cargo install --locked --path sign
$ cargo install --locked --path control
$ kore-keygen -h
$ kore-sign -h
$ kore-patch -h
TIP
Estas utilidades pueden usarse con relativa frecuencia, por lo que recomendamos que incluya los scripts en el PATH para simplificar su uso.Kore Keygen
Cualquier nodo Kore necesita material criptográfico para funcionar. Para ello es necesario generarlo externamente y luego indicarlo al nodo, ya sea mediante variables de entorno o mediante parámetros de entrada. La utilidad Kore Keygen satisface esta necesidad permitiendo, de forma sencilla, la generación de este material criptográfico. En concreto, su ejecución permite obtener una clave privada en formato hexadecimal, así como el identificador (controller ID) que es el identificador a nivel Kore en el que su formato incluye la clave pública. , más información del esquema criptográfico utilizado (puede obtener más información en el siguiente link).
# Generate pkcs8 encrpty with pkcs5(ED25519)
kore-keygen -p a
kore-keygen -p a -r keys-Ed25519/private_key.der
kore-keygen -p a -r keys-Ed25519/public_key.der -d public-key
# Generate pkcs8 encrpty with pkcs5(SECP256K1)
kore-keygen -p a -m secp256k1
kore-keygen -p a -r keys-secp2561k/private_key.der -m secp256k1
kore-keygen -p a -r keys-secp2561k/public_key.der -m secp256k1 -d public-key
INFO
X y las otras herramientas aceptan diferentes argumentos de ejecución. Para obtener más información, intente –help, por ejemplo:
kore-keygen --help
Kore Sign
Esta es una utilidad que tiene como objetivo facilitar la ejecución de invocaciones externas. Para proporcionar contexto, una invocación externa es el proceso mediante el cual un nodo propone un cambio a un sujeto de la red que no controla, es decir, de del que no es propietario. También existen una serie de reglas que regulan qué usuarios de la red tienen la capacidad de realizar estas operaciones. En cualquiera de los casos, el nodo invocante deberá presentar, además de los cambios que desee sugerir, una firma válida que acredite su identidad.
Kore Sign permite precisamente esto último, generando la firma necesaria para acompañar la solicitud de cambios. Además, como la utilidad está estrictamente diseñada para tal escenario, lo que realmente devuelve su ejecución es la estructura de datos completa (en formato JSON) que debe entregarse a otros nodos de la red para que consideren la solicitud.
Para el correcto funcionamiento de la utilidad es necesario pasar como argumentos tanto los datos de solicitud del evento como la clave privada en formato hexadecimal a utilizar.
# Ejemplo uso básico
kore-sign --id-private-key 2a71a0aff12c2de9e21d76e0538741aa9ac6da9ff7f467cf8b7211bd008a3198 '{"Transfer":{"subject_id":"JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU","public_key":"E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"}}'
// Salida en fomato json
{
"request": {
"Transfer": {
"subject_id": "JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU",
"public_key": "E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"
}
},
"signature": {
"signer": "EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA",
"timestamp": 1717684953822643000,
"content_hash": "J1XWoQaLArB5q6B_PCfl4nzT36qqgoHzG-Uh32L_Q3cY",
"value": "SEYml_XhryHvxRylu023oyR0nIjlwVCyw2ZC_Tgvf04W8DnEzP9I3fFpHIc0eHrp46Exk8WIlG6fT1qp1bg1WgAg"
}
}
CAUTION
Es importante tener en cuenta que actualmente solo se admiten claves privadas del algoritmo ED25519TIP
Si necesita pasar la solicitud de evento a Kore-sign a través de una pipe en lugar de como argumento, puede usar xargs utilidad. Por ejemplo,
echo '{"Transfer":{"subject_id":"JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU","public_key":"E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"}}' | xargs -0 -I {} kore-sign --id-private-key 2a71a0aff12c2de9e21d76e0538741aa9ac6da9ff7f467cf8b7211bd008a3198 {}
Kore Patch
Actualmente, el contrato que maneja los cambios de gobernanza solo permite un tipo de evento que incluye un JSON Patch.
JSON Patch es un formato de datos que representa cambios en las estructuras de datos JSON. Así, partiendo de una estructura inicial, tras aplicar el JSON-Patch se obtiene una estructura actualizada. En el caso de Kore, el JSON Patch define los cambios que se realizarán en la estructura de datos que representa la gobernanza cuando es necesario modificarla. Kore Patch nos permite calcular el JSON Patch de forma sencilla si tenemos la gobernanza original y la gobernanza modificada.
# Ejemplos de uso básico
kore-patch '{"members":[]}' '{"members":[{"id":"EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA","name":"ACME"}]}'
// Salida en formato json
[
{
"op": "add",
"path": "/members/0",
"value": {
"id": "EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA",
"name": "ACME"
}
}
]
Una vez que se obtiene el JSON Patch, se puede incluir en una solicitud de evento que se enviará al propietario del gobierno.
TIP
Aunque Kore Patch se desarrolló para facilitar modificaciones en la gobernanza de Kore, en realidad es solo una utilidad que genera un JSON PATH a partir de 2 objetos JSON, por lo que puede usarse para otros fines.Control
Herramienta para proporcionar una lista de permitidos y bloqueados a los nodos. Dispone de 3 variables de entorno SERVERS que permite indicar cuantos servidores quieres y en que puerto quieres que escuchen y dos listas ALLOWLIST y BLOCKLIST. Estas listas seran las por defecto pero se dispone de una ruta /allow y /block con PUT y GET para modificarlas.
export SERVERS="0.0.0.0:3040,0.0.0.0:3041"
export ALLOWLIST="172.10.10.2"
control
Salida
Server started at: 0.0.0.0:3040
Server started at: 0.0.0.0:3041
4 - Políticas
Documentos de políticas de Kore Ledger.
4.1 - Aviso legal
Declaración de aviso legal de Kore Ledger.
1. Información legal
Este sitio web es propiedad de Kore Ledger, S.L., con domicilio en Calle Tomas Baulen Y Ponte 72 38500. 38500, Guimar (Santa Cruz De Tenerife) España y número de identificación fiscal B56696545.
2. Condiciones de uso
Al acceder y utilizar este sitio web, aceptas cumplir con los siguientes términos y condiciones de uso. Si no estás de acuerdo con estos términos, por favor, abstente de utilizar el sitio.
3. Propiedad intelectual
Todos los contenidos de este sitio web, incluyendo, pero no limitado a, texto, gráficos, logotipos, imágenes y software, son propiedad de Kore Ledge y están protegidos por las leyes de propiedad intelectual españolas. Queda prohibida su reproducción, distribución o modificación sin el consentimiento expreso del titular de este sitio web.
4. Privacidad
La información personal recopilada a través de este sitio se utiliza de acuerdo con nuestra Política de Privacidad, la cual puedes consultar en este enlace.
5.Limitación de responsabilidad
Kore Ledger no se hace responsable de los daños directos o indirectos resultantes del uso de este sitio web, incluyendo la pérdida de datos, interrupciones de servicio o cualquier otro problema técnico.
6. Enlaces
Desde este sitio web puede que se mencionen enlaces a otros sitios web. Kore Ledger no es responsable de la disponibilidad, contenidos y posibles daños o perjuicios sufridos por visitar dichos sitios web ya que se rigen por sus propios términos y condiciones y respecto de los cuales Kore Ledger no tiene ningún control.
7. Ley aplicable y jurisdicción
Este aviso legal se rige por las leyes españolas, y cualquier disputa relacionada con este aviso legal estará sujeta a la jurisdicción de los tribunales de Santa Cruz de Tenerife.
8. Modificaciones
Nos reservamos el derecho de realizar cambios en este aviso legal en cualquier momento. Los cambios serán efectivos tan pronto como se publiquen en el sitio.
9. Contacto
Si tienes alguna pregunta o comentario sobre este aviso legal, por favor contáctanos en: support@kore-ledger.net.
4.2 - Privacidad
Declaración de privacidad de Kore Ledger.
1. Información sobre el responsable del tratamiento
- Responsable del tratamiento: Kore Ledger, S.L.
- Domicilio social: Calle Tomas Baulen Y Ponte 72 38500, Güímar (Santa Cruz De Tenerife)
- Número de identificación fiscal: B56696545
- Correo electrónico de contacto: support@kore-ledger.net
2. Tratamiento de datos personales
Recopilamos y tratamos los datos personales de los usuarios de este sitio web de acuerdo con la legislación española y el RGPD. Los datos personales se recopilan de forma transparente y se utilizan únicamente para los fines específicos para los cuales fueron proporcionados.
3. Finalidades del tratamiento de datos
Los datos personales se recopilan con los siguientes fines:
- Envío de información sobre productos, promociones o actualizaciones relevantes.
- Atención al cliente y soporte.
4. Base legal para el tratamiento
La base legal para el tratamiento de datos personales es el consentimiento del usuario y los intereses legítimos perseguidos por Kore Ledger, S.L.
5. Consentimiento del usuario
Al proporcionar tus datos personales, consientes expresamente el tratamiento de los mismos para las finalidades indicadas en esta política de privacidad.
6. Derechos de los usuarios
Los usuarios tienen derecho a acceder, rectificar, cancelar y oponerse al tratamiento de sus datos personales. Para ejercer estos derechos, pueden ponerse en contacto con nosotros a través de support@kore-ledger.net. Podrás encontrar formularios para el ejercicio de tus derechos en: https://www.aepd.es/derechos-y-deberes/conoce-tus-derechos En caso de que consideres que tus datos están siendo tratados de manera inadecuada podrás presentar una reclamación ante la autoridad de control (Agencia Española de Protección de Datos). Para más información sobre este punto puedes consultar: https://www.aepd.es/preguntas-frecuentes/13-reclamaciones-ante-aepd-y-ante-otros-organismos-competentes/FAQ-1301-como-puedo-interponer-una-reclamacion-si-han-vulnerado-mis-datos-de-caracter-personal
7. Compartir datos con terceros
No compartimos datos personales con terceros, excepto cuando sea necesario para cumplir con obligaciones legales o para la prestación de servicios relacionados con el funcionamiento del sitio web.
8. Seguridad de los datos
Adoptamos medidas de seguridad adecuadas para proteger los datos personales contra pérdida, uso indebido o acceso no autorizado.
9. Cookies
Este sitio web utiliza cookies para mejorar la experiencia del usuario. Puedes obtener más información en nuestra Política de Cookies [enlace a la política de cookies].
10. Cambios en la política de privacidad
Nos reservamos el derecho de realizar cambios en esta política de privacidad. Cualquier modificación será notificada en esta página.
11. Contacto
Para cualquier pregunta o comentario sobre esta política de privacidad, por favor contáctanos a través de nuestro correo electrónico de contacto: support@kore-ledger.net.
4.3 - Igualdad y diversidad
Kore ledger compromiso con la igualdad y la diversidad.
El compromiso de Kore Ledger con la igualdad y la diversidad.
Kore Ledger, S.L. declara su compromiso en el establecimiento y desarrollo de políticas que integren la igualdad de trato y oportunidades entre mujeres y hombres, sin discriminar directa o indirectamente por razón de sexo, así como en el impuso y fomento de medidas para conseguir la igualdad real en el seno de nuestra organización, estableciendo la igualdad de oportunidades entre mujeres y hombres como un principio estratégico de nuestra Política Corporativa y de Recursos Humanos, de acuerdo con la definición de dicho principio que establece la Ley Orgánica 3/2007, de 22 de marzo, para la igualdad efectiva entre mujeres y hombres.
En todos y cada uno de los ámbitos en que se desarrolla la actividad de esta empresa, desde la selección a la promoción, pasando por la política salarial, la formación, las condiciones de trabajo y empleo, la salud laboral, la ordenación del tiempo de trabajo y la conciliación, asumimos el principio de igualdad de oportunidades entre mujeres y hombres, atendiendo de forma especial a la discriminación indirecta, entendiendo por ésta “La situación en que una disposición, criterio o práctica aparentemente neutros, pone a una persona de un sexo en desventaja particular respecto de personas del otro sexo”.
Respecto a la comunicación, tanto interna como externa, se informará de todas las decisiones que se adopten a este respecto y se proyectará una imagen de la empresa acorde con este principio de igualdad de oportunidades entre mujeres y hombres.
Los principios enunciados se llevarán a la práctica a través del fomento de medidas de igualdad o a través de la implantación de un Plan de igualdad que supongan mejoras respecto a la situación presente, arbitrándose los correspondientes sistemas de seguimiento, con la finalidad de avanzar en la consecución de la igualdad real entre mujeres y hombres en la empresa y por extensión, en el conjunto de la sociedad.
Para llevar a cabo este propósito se contará con la representación legal de trabajadores y trabajadoras, no sólo en el proceso de negociación colectiva, tal y como establece la Ley Orgánica 3/2007 para la igualdad efectiva entre mujeres y hombres, sino en todo el proceso de desarrollo y evaluación de las mencionadas medidas de igualdad o Plan de igualdad.