This is the multi-page printable view of this section. Click here to print.
Learn
- 1: Governance
- 2: Contracts
- 2.1: Contracts in Kore
- 2.2: Programming contracts
- 3: Learn JSON Schema
- 4: Kore Base
- 4.1: Architecture
- 4.2: FFI
- 5: Kore Node
- 5.1: What is
- 5.2: Configuration
- 6: Kore Clients
- 6.1: Kore HTTP
- 6.2: Kore Modbus
- 7: Tools
1 - Governance
1.1 - Governance structure
In this page we will describe the governance structure and configuration. If you want to know more about what governance visit the Governance page.
GOVERNANCE EXAMPLE
Click to look a full governance example. Each section will be discussed separately in the following sections.
{
"members": [
{
"name": "Company1",
"id": "ED8MpwKh3OjPEw_hQdqJixrXlKzpVzdvHf2DqrPvdz7Y"
},
{
"name": "Company2",
"id": "EXjEOmKsvlXvQdEz1Z6uuDO_zJJ8LNDuPi6qPGuAwePU"
}
],
"schemas": [
{
"id": "Test",
"schema": {
"type": "object",
"additionalProperties": false,
"required": ["temperature", "location"],
"properties": {
"temperatura": {
"type": "integer"
},
"localizacion": {
"type": "string"
}
}
},
"initial_value": {
"temperatura": 0,
"localizacion": ""
},
"contract": {
"raw": "dXNlIHNlcmRlOjp7U2VyaWFsaXplLCBEZXNlcmlhbGl6ZX07Cgptb2Qgc2RrOwoKI1tkZXJpdmUoU2VyaWFsaXplLCBEZXNlcmlhbGl6ZSwgQ2xvbmUpXQpzdHJ1Y3QgU3RhdGUgewogIHB1YiBvbmU6IHUzMiwKICBwdWIgdHdvOiB1MzIsCiAgcHViIHRocmVlOiB1MzIKfQoKI1tkZXJpdmUoU2VyaWFsaXplLCBEZXNlcmlhbGl6ZSldCmVudW0gU3RhdGVFdmVudCB7CiAgTW9kT25lIHsgZGF0YTogdTMyIH0sCiAgTW9kVHdvIHsgZGF0YTogdTMyIH0sCiAgTW9kVGhyZWUgeyBkYXRhOiB1MzIgfSwKICBNb2RBbGwgeyBvbmU6IHUzMiwgdHdvOiB1MzIsIHRocmVlOiB1MzIgfQp9CgojW25vX21hbmdsZV0KcHViIHVuc2FmZSBmbiBtYWluX2Z1bmN0aW9uKHN0YXRlX3B0cjogaTMyLCBldmVudF9wdHI6IGkzMiwgaXNfb3duZXI6IGkzMikgLT4gdTMyIHsKICAgIHNkazo6ZXhlY3V0ZV9jb250cmFjdChzdGF0ZV9wdHIsIGV2ZW50X3B0ciwgaXNfb3duZXIsIGNvbnRyYWN0X2xvZ2ljKQp9CgpmbiBjb250cmFjdF9sb2dpYygKICBjb250ZXh0OiAmc2RrOjpDb250ZXh0PFN0YXRlLCBTdGF0ZUV2ZW50PiwKICBjb250cmFjdF9yZXN1bHQ6ICZtdXQgc2RrOjpDb250cmFjdFJlc3VsdDxTdGF0ZT4sCikgewogIGxldCBzdGF0ZSA9ICZtdXQgY29udHJhY3RfcmVzdWx0LmZpbmFsX3N0YXRlOwogIG1hdGNoIGNvbnRleHQuZXZlbnQgewogICAgICBTdGF0ZUV2ZW50OjpNb2RPbmUgeyBkYXRhIH0gPT4gewogICAgICAgIHN0YXRlLm9uZSA9IGRhdGE7CiAgICAgIH0sCiAgICAgIFN0YXRlRXZlbnQ6Ok1vZFR3byB7IGRhdGEgfSA9PiB7CiAgICAgICAgc3RhdGUudHdvID0gZGF0YTsKICAgICAgfSwKICAgICAgU3RhdGVFdmVudDo6TW9kVGhyZWUgeyBkYXRhIH0gPT4gewogICAgICAgIHN0YXRlLnRocmVlID0gZGF0YTsKICAgICAgfSwKICAgICAgU3RhdGVFdmVudDo6TW9kQWxsIHsgb25lLCB0d28sIHRocmVlIH0gPT4gewogICAgICAgIHN0YXRlLm9uZSA9IG9uZTsKICAgICAgICBzdGF0ZS50d28gPSB0d287CiAgICAgICAgc3RhdGUudGhyZWUgPSB0aHJlZTsKICAgICAgfQogIH0KICBjb250cmFjdF9yZXN1bHQuc3VjY2VzcyA9IHRydWU7Cn0="
}
}
],
"policies": [
{
"id": "Test",
"validate": {
"quorum": {
"PROCENTAJE": 0.5
}
},
"evaluate": {
"quorum": "MAJORITY"
},
"approve": {
"quorum": {
"FIXED": 1
}
}
},
{
"id": "governance",
"validate": {
"quorum": {
"PROCENTAJE": 0.5
}
},
"evaluate": {
"quorum": "MAJORITY"
},
"approve": {
"quorum": {
"FIXED": 1
}
}
}
],
"roles": [
{
"who": "MEMBERS",
"namespace": "",
"role": "CREATOR",
"schema": {
"ID": "Test"
}
},
{
"who": "MEMBERS",
"namespace": "",
"role": "WITNESS",
"schema": {
"ID": "Test"
}
},
{
"who": "MEMBERS",
"namespace": "",
"role": "EVALUATOR",
"schema": "ALL"
},
{
"who": {
"NAME": "Company1"
},
"namespace": "",
"role": "APPROVER",
"schema": "ALL"
}
]
}
Members
This property allows us to define the conditions that must be met in the different phases of generating an event that requires the participation of different members, such as approval, evaluation, and validation.
- name: A short, colloquial name by which the node is known in the network. It serves no functionality other than being descriptive. It does not act as a unique identifier within the governance.
- id: Corresponds to the controller-id of the node. Acts as a unique identifier within the network and corresponds to the node’s cryptographic public key.
Schemas
Defines the list of schemas that are allowed to be used in the subjects associated with governance. Each scheme includes the following properties:
- id: Schema unique identifier.
- schema: Schema description in JSON-Schema format.
- initial_value: JSON Object that represents the initial state of a newly created subject for this schema.
- contract: The compiled contract in Raw String base 64.
Roles
In this section, we define who are in charge of giving their consent for the event to progress through the different phases of its life cycle (evaluation, approval, and validation), and on the other hand, it also serves to indicate who can perform certain actions (creation of subjects and external invocation).
- who: Indicates who the Role affects, it can be a specific id (public key), a member of the governance identified by their name, all members, both members and outsiders, or only outsiders.
- ID{ID}: Public Key of the member.
- NAME{NAME}: Name of the member.
- MEMBERS: All members.
- ALL: All members and externs.
- NOT_MEMBERS: All externs.
- namespace: It makes the role in question only valid if it matches the namespace of the subject for which the list of signatories or permissions is being obtained. If it is not present or it’s empty, it’s assumed to apply universally, as if it were the wildcard
*. For the time being, we are not supporting complex wildcards, but implicitly, if we set a namespace, it encompasses everything below it. For instance:- open is equivalent to
open*, but not toopen - open.dev is equivalent to
open.dev*, but not toopen.dev - If it’s empty, it equates to everything, that is,
*.
- open is equivalent to
- role: Indicates what phase it affects:
- VALIDATOR: For the validation phase.
- CREATOR: Indicates who can create subjects of this type.
- ISSUER: Indicates who can invoke the external invocation of this type.
- WITNESS: Indicates who are the witness of the subject.
- APPROVER: Indicates who are the approvators of the subject. Required for the approval phase.
- EVALUATOR: Indicates who are the evaluators of the subject. Required for the evaluation phase.
- schema: Indicates which schemas are affected by the Role. They can be specified by their id, all or those that are not governance.
- ID{ID}: Schema unique identifier.
- NOT_GOVERNANCE: All schemas except governance.
- ALL: All schemas.
Policies
This property defines the permissions of the users previously defined in the members section, granting them roles with respect to the schemas they have defined. Policies are defined independently for each scheme defined in governance.
- approve: Defines who the approvators are for the subjects that are created with that schema. Also, the quorum required to consider an event as approved.
- evaluate: Defines who the evaluators are for the subjects that are created with that schema. Also, the quorum required to consider an event as evaluated.
- validate: Defines who the validators are for the subjects that are created with that schema. Also, the quorum required to consider an event as validated.
What these data define is the type of quorum that must be reached for the event to pass this phase. There are 3 types of quorum:
- MAJORITY: This is the simplest one, it means that the majority, that is, more than 50% of the voters must sign the petition. It always rounds up, for example, in the case where there are 4 voters, the MAJORITY quorum would be reached when 3 give their signature.
- FIXED{fixed}: It’s pretty straightforward, it means that a fixed number of voters must sign the petition. For example, if a FIXED quorum of 3 is specified, this quorum will be reached when 3 voters have signed the petition.
- PERCENTAGE{percentage}: This is a quorum that is calculated based on a percentage of the voters. For example, if a PERCENTAGE quorum of 0.5 is specified, this quorum will be reached when 50% of the voters have signed the petition. It always rounds up.
In the event that a policy does not resolve for any member it will be returned to the governance owner. This allows, for example, that after the creation of the governance, when there are no declared members yet, the owner can evaluate, approve and validate the changes.
CAUTION
It is necessary to specify the permissions of all the schemes that are defined, there is no default assignment. Due to this, it is also necessary to specify the permissions of the governance scheme.1.2 - Governance scheme and contract
Governances in Kore are special subjects. Governances have a specific schema and contract defined within the Kore code. This is the case because prior configuration is necessary. This schema and contract must be the same for all participants in a network, otherwise failures can occur because a different result is expected, or the schema is valid for one participant but not for another. This schema and contract do not appear explicitly in the governance itself, but are within Kore and cannot be modified.
GOVERNANCE SCHEMA
Click to look at the full governance schema.
{
"$defs": {
"role": {
"type": "string",
"enum": ["VALIDATOR", "CREATOR", "ISSUER", "WITNESS", "APPROVER", "EVALUATOR"]
},
"quorum": {
"oneOf": [
{
"type": "string",
"enum": ["MAJORITY"]
},
{
"type": "object",
"properties": {
"FIXED": {
"type": "number",
"minimum": 1,
"multipleOf": 1
}
},
"required": ["FIXED"],
"additionalProperties": false
},
{
"type": "object",
"properties": {
"PERCENTAGE": {
"type": "number",
"minimum": 0,
"maximum": 1
}
},
"required": ["PERCENTAGE"],
"additionalProperties": false
}
]
}
},
"type": "object",
"additionalProperties": false,
"required": [
"members",
"schemas",
"policies",
"roles"
],
"properties": {
"members": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"id": {
"type": "string",
"format": "keyidentifier"
}
},
"required": [
"id",
"name"
],
"additionalProperties": false
}
},
"roles": {
"type": "array",
"items": {
"type": "object",
"properties": {
"who": {
"oneOf": [
{
"type": "object",
"properties": {
"ID": {
"type": "string"
}
},
"required": ["ID"],
"additionalProperties": false
},
{
"type": "object",
"properties": {
"NAME": {
"type": "string"
}
},
"required": ["NAME"],
"additionalProperties": false
},
{
"const": "MEMBERS"
},
{
"const": "ALL"
},
{
"const": "NOT_MEMBERS"
}
]
},
"namespace": {
"type": "string"
},
"role": {
"$ref": "#/$defs/role"
},
"schema": {
"oneOf": [
{
"type": "object",
"properties": {
"ID": {
"type": "string"
}
},
"required": ["ID"],
"additionalProperties": false
},
{
"const": "ALL"
},
{
"const": "NOT_GOVERNANCE"
}
]
}
},
"required": ["who", "role", "schema", "namespace"],
"additionalProperties": false
}
},
"schemas": {
"type": "array",
"minItems": 0,
"items": {
"type": "object",
"properties": {
"id": {
"type": "string"
},
"schema": {
"$schema": "http://json-schema.org/draft/2020-12/schema",
"$id": "http://json-schema.org/draft/2020-12/schema",
"$vocabulary": {
"http://json-schema.org/draft/2020-12/vocab/core": true,
"http://json-schema.org/draft/2020-12/vocab/applicator": true,
"http://json-schema.org/draft/2020-12/vocab/unevaluated": true,
"http://json-schema.org/draft/2020-12/vocab/validation": true,
"http://json-schema.org/draft/2020-12/vocab/meta-data": true,
"http://json-schema.org/draft/2020-12/vocab/format-annotation": true,
"http://json-schema.org/draft/2020-12/vocab/content": true
},
"$dynamicAnchor": "meta",
"title": "Core and validation specifications meta-schema",
"allOf": [
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/core",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/core": true
},
"$dynamicAnchor": "meta",
"title": "Core vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"$id": {
"$ref": "#/$defs/uriReferenceString",
"$comment": "Non-empty fragments not allowed.",
"pattern": "^[^#]*#?$"
},
"$schema": {
"$ref": "#/$defs/uriString"
},
"$ref": {
"$ref": "#/$defs/uriReferenceString"
},
"$anchor": {
"$ref": "#/$defs/anchorString"
},
"$dynamicRef": {
"$ref": "#/$defs/uriReferenceString"
},
"$dynamicAnchor": {
"$ref": "#/$defs/anchorString"
},
"$vocabulary": {
"type": "object",
"propertynames": {
"$ref": "#/$defs/uriString"
},
"additionalProperties": {
"type": "boolean"
}
},
"$comment": {
"type": "string"
},
"$defs": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
}
}
},
"$defs": {
"anchorString": {
"type": "string",
"pattern": "^[A-Za-z_][-A-Za-z0-9._]*$"
},
"uriString": {
"type": "string",
"format": "uri"
},
"uriReferenceString": {
"type": "string",
"format": "uri-reference"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/applicator",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/applicator": true
},
"$dynamicAnchor": "meta",
"title": "Applicator vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"prefixItems": {
"$ref": "#/$defs/schemaArray"
},
"items": {
"$dynamicRef": "#meta"
},
"contains": {
"$dynamicRef": "#meta"
},
"additionalProperties": {
"$dynamicRef": "#meta"
},
"properties": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"default": {}
},
"patternProperties": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"propertynames": {
"format": "regex"
},
"default": {}
},
"dependentschemas": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"default": {}
},
"propertynames": {
"$dynamicRef": "#meta"
},
"if": {
"$dynamicRef": "#meta"
},
"then": {
"$dynamicRef": "#meta"
},
"else": {
"$dynamicRef": "#meta"
},
"allOf": {
"$ref": "#/$defs/schemaArray"
},
"anyOf": {
"$ref": "#/$defs/schemaArray"
},
"oneOf": {
"$ref": "#/$defs/schemaArray"
},
"not": {
"$dynamicRef": "#meta"
}
},
"$defs": {
"schemaArray": {
"type": "array",
"minItems": 1,
"items": {
"$dynamicRef": "#meta"
}
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/unevaluated",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/unevaluated": true
},
"$dynamicAnchor": "meta",
"title": "Unevaluated applicator vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"unevaluatedItems": {
"$dynamicRef": "#meta"
},
"unevaluatedProperties": {
"$dynamicRef": "#meta"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/validation",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/validation": true
},
"$dynamicAnchor": "meta",
"title": "validation vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"type": {
"anyOf": [
{
"$ref": "#/$defs/simpleTypes"
},
{
"type": "array",
"items": {
"$ref": "#/$defs/simpleTypes"
},
"minItems": 1,
"uniqueItems": true
}
]
},
"const": true,
"enum": {
"type": "array",
"items": true
},
"multipleOf": {
"type": "number",
"exclusiveMinimum": 0
},
"maximum": {
"type": "number"
},
"exclusiveMaximum": {
"type": "number"
},
"minimum": {
"type": "number"
},
"exclusiveMinimum": {
"type": "number"
},
"maxLength": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minLength": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"pattern": {
"type": "string",
"format": "regex"
},
"maxItems": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minItems": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"uniqueItems": {
"type": "boolean",
"default": false
},
"maxContains": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minContains": {
"$ref": "#/$defs/nonNegativeInteger",
"default": 1
},
"maxProperties": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minProperties": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"required": {
"$ref": "#/$defs/stringArray"
},
"dependentRequired": {
"type": "object",
"additionalProperties": {
"$ref": "#/$defs/stringArray"
}
}
},
"$defs": {
"nonNegativeInteger": {
"type": "integer",
"minimum": 0
},
"nonNegativeIntegerDefault0": {
"$ref": "#/$defs/nonNegativeInteger",
"default": 0
},
"simpleTypes": {
"enum": [
"array",
"boolean",
"integer",
"null",
"number",
"object",
"string"
]
},
"stringArray": {
"type": "array",
"items": {
"type": "string"
},
"uniqueItems": true,
"default": []
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/meta-data",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/meta-data": true
},
"$dynamicAnchor": "meta",
"title": "Meta-data vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"title": {
"type": "string"
},
"description": {
"type": "string"
},
"default": true,
"deprecated": {
"type": "boolean",
"default": false
},
"readOnly": {
"type": "boolean",
"default": false
},
"writeOnly": {
"type": "boolean",
"default": false
},
"examples": {
"type": "array",
"items": true
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/format-annotation",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/format-annotation": true
},
"$dynamicAnchor": "meta",
"title": "Format vocabulary meta-schema for annotation results",
"type": [
"object",
"boolean"
],
"properties": {
"format": {
"type": "string"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/content",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/content": true
},
"$dynamicAnchor": "meta",
"title": "content vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"contentEncoding": {
"type": "string"
},
"contentMediaType": {
"type": "string"
},
"contentschema": {
"$dynamicRef": "#meta"
}
}
}
],
"type": [
"object",
"boolean"
],
"$comment": "This meta-schema also defines keywords that have appeared in previous drafts in order to prevent incompatible extensions as they remain in common use.",
"properties": {
"definitions": {
"$comment": "\"definitions\" has been replaced by \"$defs\".",
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"deprecated": true,
"default": {}
},
"dependencies": {
"$comment": "\"dependencies\" has been split and replaced by \"dependentschemas\" and \"dependentRequired\" in order to serve their differing semantics.",
"type": "object",
"additionalProperties": {
"anyOf": [
{
"$dynamicRef": "#meta"
},
{
"$ref": "meta/validation#/$defs/stringArray"
}
]
},
"deprecated": true,
"default": {}
},
"$recursiveAnchor": {
"$comment": "\"$recursiveAnchor\" has been replaced by \"$dynamicAnchor\".",
"$ref": "meta/core#/$defs/anchorString",
"deprecated": true
},
"$recursiveRef": {
"$comment": "\"$recursiveRef\" has been replaced by \"$dynamicRef\".",
"$ref": "meta/core#/$defs/uriReferenceString",
"deprecated": true
}
}
},
"initial_value": {},
"contract": {
"type": "object",
"properties": {
"raw": {
"type": "string"
},
},
"additionalProperties": false,
"required": ["raw"]
},
},
"required": [
"id",
"schema",
"initial_value",
"contract"
],
"additionalProperties": false
}
},
"policies": {
"type": "array",
"items": {
"type": "object",
"additionalProperties": false,
"required": [
"id", "approve", "evaluate", "validate"
],
"properties": {
"id": {
"type": "string"
},
"approve": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
},
"evaluate": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
},
"validate": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
}
}
}
}
}
}
And its initial state is:
{
"members": [],
"roles": [
{
"namespace": "",
"role": "WITNESS",
"schema": {
"ID": "governance"
},
"who": "MEMBERS"
}
],
"schemas": [],
"policies": [
{
"id": "governance",
"approve": {
"quorum": "MAJORITY"
},
"evaluate": {
"quorum": "MAJORITY"
},
"validate": {
"quorum": "MAJORITY"
}
}
]
}
Essentially, the initial state of the governance defines that all members added to the governance will be witnesses, and a majority of signatures from all members is required for any of the phases in the lifecycle of governance change events. However, it does not have any additional schemas, which will need to be added according to the needs of the use cases.
The governance contract is:
mod sdk;
use std::collections::HashSet;
use thiserror::Error;
use sdk::ValueWrapper;
use serde::{de::Visitor, ser::SerializeMap, Deserialize, Serialize};
#[derive(Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum Who {
ID { ID: String },
NAME { NAME: String },
MEMBERS,
ALL,
NOT_MEMBERS,
}
impl Serialize for Who {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: serde::Serializer,
{
match self {
Who::ID { ID } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("ID", ID)?;
map.end()
}
Who::NAME { NAME } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("NAME", NAME)?;
map.end()
}
Who::MEMBERS => serializer.serialize_str("MEMBERS"),
Who::ALL => serializer.serialize_str("ALL"),
Who::NOT_MEMBERS => serializer.serialize_str("NOT_MEMBERS"),
}
}
}
impl<'de> Deserialize<'de> for Who {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
struct WhoVisitor;
impl<'de> Visitor<'de> for WhoVisitor {
type Value = Who;
fn expecting(&self, formatter: &mut std::fmt::Formatter) -> std::fmt::Result {
formatter.write_str("Who")
}
fn visit_map<A>(self, mut map: A) -> Result<Self::Value, A::Error>
where
A: serde::de::MapAccess<'de>,
{
// They should only have one entry
let Some(key) = map.next_key::<String>()? else {
return Err(serde::de::Error::missing_field("ID or NAME"))
};
let result = match key.as_str() {
"ID" => {
let id: String = map.next_value()?;
Who::ID { ID: id }
}
"NAME" => {
let name: String = map.next_value()?;
Who::NAME { NAME: name }
}
_ => return Err(serde::de::Error::unknown_field(&key, &["ID", "NAME"])),
};
let None = map.next_key::<String>()? else {
return Err(serde::de::Error::custom("Input data is not valid. The data contains unkown entries"));
};
Ok(result)
}
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v.as_str() {
"MEMBERS" => Ok(Who::MEMBERS),
"ALL" => Ok(Who::ALL),
"NOT_MEMBERS" => Ok(Who::NOT_MEMBERS),
other => Err(serde::de::Error::unknown_variant(
other,
&["MEMBERS", "ALL", "NOT_MEMBERS"],
)),
}
}
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v {
"MEMBERS" => Ok(Who::MEMBERS),
"ALL" => Ok(Who::ALL),
"NOT_MEMBERS" => Ok(Who::NOT_MEMBERS),
other => Err(serde::de::Error::unknown_variant(
other,
&["MEMBERS", "ALL", "NOT_MEMBERS"],
)),
}
}
}
deserializer.deserialize_any(WhoVisitor {})
}
}
#[derive(Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum SchemaEnum {
ID { ID: String },
NOT_GOVERNANCE,
ALL,
}
impl Serialize for SchemaEnum {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: serde::Serializer,
{
match self {
SchemaEnum::ID { ID } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("ID", ID)?;
map.end()
}
SchemaEnum::NOT_GOVERNANCE => serializer.serialize_str("NOT_GOVERNANCE"),
SchemaEnum::ALL => serializer.serialize_str("ALL"),
}
}
}
impl<'de> Deserialize<'de> for SchemaEnum {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
struct SchemaEnumVisitor;
impl<'de> Visitor<'de> for SchemaEnumVisitor {
type Value = SchemaEnum;
fn expecting(&self, formatter: &mut std::fmt::Formatter) -> std::fmt::Result {
formatter.write_str("Schema")
}
fn visit_map<A>(self, mut map: A) -> Result<Self::Value, A::Error>
where
A: serde::de::MapAccess<'de>,
{
// They should only have one entry
let Some(key) = map.next_key::<String>()? else {
return Err(serde::de::Error::missing_field("ID"))
};
let result = match key.as_str() {
"ID" => {
let id: String = map.next_value()?;
SchemaEnum::ID { ID: id }
}
_ => return Err(serde::de::Error::unknown_field(&key, &["ID", "NAME"])),
};
let None = map.next_key::<String>()? else {
return Err(serde::de::Error::custom("Input data is not valid. The data contains unkown entries"));
};
Ok(result)
}
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v.as_str() {
"ALL" => Ok(Self::Value::ALL),
"NOT_GOVERNANCE" => Ok(Self::Value::NOT_GOVERNANCE),
other => Err(serde::de::Error::unknown_variant(
other,
&["ALL", "NOT_GOVERNANCE"],
)),
}
}
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v {
"ALL" => Ok(Self::Value::ALL),
"NOT_GOVERNANCE" => Ok(Self::Value::NOT_GOVERNANCE),
other => Err(serde::de::Error::unknown_variant(
other,
&["ALL", "NOT_GOVERNANCE"],
)),
}
}
}
deserializer.deserialize_any(SchemaEnumVisitor {})
}
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Role {
who: Who,
namespace: String,
role: RoleEnum,
schema: SchemaEnum,
}
#[derive(Serialize, Deserialize, Clone)]
pub enum RoleEnum {
VALIDATOR,
CREATOR,
ISSUER,
WITNESS,
APPROVER,
EVALUATOR,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Member {
id: String,
name: String,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Contract {
raw: String,
}
#[derive(Serialize, Deserialize, Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum Quorum {
MAJORITY,
FIXED(u64),
PERCENTAGE(f64),
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Validation {
quorum: Quorum,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Policy {
id: String,
approve: Validation,
evaluate: Validation,
validate: Validation,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Schema {
id: String,
schema: serde_json::Value,
initial_value: serde_json::Value,
contract: Contract,
}
#[repr(C)]
#[derive(Serialize, Deserialize, Clone)]
pub struct Governance {
members: Vec<Member>,
roles: Vec<Role>,
schemas: Vec<Schema>,
policies: Vec<Policy>,
}
// Define "Event family".
#[derive(Serialize, Deserialize, Debug)]
pub enum GovernanceEvent {
Patch { data: ValueWrapper },
}
#[no_mangle]
pub unsafe fn main_function(state_ptr: i32, event_ptr: i32, is_owner: i32) -> u32 {
sdk::execute_contract(state_ptr, event_ptr, is_owner, contract_logic)
}
// Contract logic with expected data types
// Returns the pointer to the data written with the modified state.
fn contract_logic(
context: &sdk::Context<Governance, GovernanceEvent>,
contract_result: &mut sdk::ContractResult<Governance>,
) {
// It would be possible to add error handling
// It could be interesting to do the operations directly as serde_json:Value instead of "Custom Data".
let state = &mut contract_result.final_state;
let _is_owner = &context.is_owner;
match &context.event {
GovernanceEvent::Patch { data } => {
// A JSON PATCH is received
// It is applied directly to the state
let patched_state = sdk::apply_patch(data.0.clone(), &context.initial_state).unwrap();
if let Ok(_) = check_governance_state(&patched_state) {
*state = patched_state;
contract_result.success = true;
contract_result.approval_required = true;
} else {
contract_result.success = false;
}
}
}
}
#[derive(Error, Debug)]
enum StateError {
#[error("A member's name is duplicated")]
DuplicatedMemberName,
#[error("A member's ID is duplicated")]
DuplicatedMemberID,
#[error("A policy identifier is duplicated")]
DuplicatedPolicyID,
#[error("No governace policy detected")]
NoGvernancePolicy,
#[error("It is not allowed to specify a different schema for the governnace")]
GovernanceShchemaIDDetected,
#[error("Schema ID is does not have a policy")]
NoCorrelationSchemaPolicy,
#[error("There are policies not correlated to any schema")]
PoliciesWithoutSchema,
}
fn check_governance_state(state: &Governance) -> Result<(), StateError> {
// We must check several aspects of the status.
// There cannot be duplicate members, either in name or ID.
check_members(&state.members)?;
// There can be no duplicate policies and the one associated with the governance itself must be present.
let policies_names = check_policies(&state.policies)?;
// Schema policies that do not exist cannot be indicated. Likewise, there cannot be
// schemas without policies. The correlation must be one-to-one
check_schemas(&state.schemas, policies_names)
}
fn check_members(members: &Vec<Member>) -> Result<(), StateError> {
let mut name_set = HashSet::new();
let mut id_set = HashSet::new();
for member in members {
if name_set.contains(&member.name) {
return Err(StateError::DuplicatedMemberName);
}
name_set.insert(&member.name);
if id_set.contains(&member.id) {
return Err(StateError::DuplicatedMemberID);
}
id_set.insert(&member.id);
}
Ok(())
}
fn check_policies(policies: &Vec<Policy>) -> Result<HashSet<String>, StateError> {
// Check that there are no duplicate policies and that the governance policy is included.
let mut is_governance_present = false;
let mut id_set = HashSet::new();
for policy in policies {
if id_set.contains(&policy.id) {
return Err(StateError::DuplicatedPolicyID);
}
id_set.insert(&policy.id);
if &policy.id == "governance" {
is_governance_present = true
}
}
if !is_governance_present {
return Err(StateError::NoGvernancePolicy);
}
id_set.remove(&String::from("governance"));
Ok(id_set.into_iter().cloned().collect())
}
fn check_schemas(
schemas: &Vec<Schema>,
mut policies_names: HashSet<String>,
) -> Result<(), StateError> {
// We check that there are no duplicate schemas.
// We also have to check that the initial states are valid according to the json_schema
// Also, there cannot be a schema with id "governance".
for schema in schemas {
if &schema.id == "governance" {
return Err(StateError::GovernanceShchemaIDDetected);
}
// There can be no duplicates and they must be matched with policies_names
if !policies_names.remove(&schema.id) {
// Not related to policies_names
return Err(StateError::NoCorrelationSchemaPolicy);
}
}
if !policies_names.is_empty() {
return Err(StateError::PoliciesWithoutSchema);
}
Ok(())
}
The governance contract is currently designed to only support one method/event - the “Patch”. This method allows us to send changes to the governance in the form of JSON-Patch, a standard format for expressing a sequence of operations to apply to a JavaScript Object Notation (JSON) document.
For instance, if we have a default governance and we want to make a change, such as adding a member, we would first calculate the JSON-Patch to express this change. This can be done using any tool that follows the JSON Patch standard RFC 6902, or with the use of our own tool, kore-patch.
This way, the governance contract leverages the flexibility of the JSON-Patch standard to allow for a wide variety of state changes while maintaining a simple and single method interface.
The contract has a close relationship with the schema, as it takes into account its definition to obtain the state before the execution of the contract and to validate it at the end of such execution.
Currently, it only has one function that can be called from an event of type Fact, the Patch method: Patch { data: ValueWrapper }. This method obtains a JSON patch that applies the changes it includes directly on the properties of the governance subject. At the end of its execution, it calls the function that checks that the final state obtained after applying the patch is a valid governance.
2 - Contracts
2.1 - Contracts in Kore
Contracts & schemas
In Kore, each subject is associated to a schema that determines, fundamentally, its properties. The value of these properties may change over time through the emission of events, being necessary, consequently, to establish the mechanism through which these events perform such action. In practice, this is managed through a series of rules that constitute what we call a contract.
Consequently, we can say that a schema always has an associated contract that regulates how it evolves. The specification of both is done in governance.
Inputs and outputs
Contracts, although specified in the governance, are only executed by those nodes that have evaluation capabilities and have been defined as such in the governance rules. It is important to note that Kore allows a node to act as evaluator of a subject even if it does not possess the subject’s events chain, i.e., even if it is not witness. This helps to reduce the load on these nodes and contributes to the overall network performance.
To achieve the correct execution of a contract, it receives three inputs: the current state of the subject, the event to be processed and a flag indicating whether or not the event request has been issued by the owner of the subject. Once these inputs are received, the contract must use them to generate a new valid state. Note that the logic of the latter lies entirely with the contract programmer. The contract programmer also determines which events are valid, i.e. decides the family of events to be used. Thus, the contract will only accept events from this family, rejecting all others, and which the programmer can adapt, in terms of structure and data, to the needs of his use case. As an example, suppose a subject representing an user’s profile with his contact information as well as his identity; an event of the family could be one that only updates the user’s telephone number. On the other hand, the flag can be used to restrict certain operations to only the owner of the subject, since the execution of the contract is performed both by the events it generates on its own and by external invocations.
When a contract is finished executing, it generates three outputs:
-
Success flag: By means of a Boolean, it indicates whether the execution of the contract has been successful, in other words, whether the event should cause a change of state of the subject. This flag will be set to false whenever an error occurs in obtaining the input data of the contract or if the logic of the contract so dictates. In other words, it can and should be explicitly stated whether or not the execution can be considered successful. This is important because these decisions depend entirely on the use case, from which Kore is abstracted in its entirety. Thus, for example, the programmer could determine that if, after the execution of an event, the value of one of the subject properties has exceeded a threshold, the event cannot be considered valid.
-
Final state: If the event has been successfully processed and the execution of the contract has been marked as successful, then it returns the new state generated, which in practice could be the same as the previous one. This state will be validated against the schema defined in the governance to ensure the integrity of the information. If the validation is not successful, the success flag is cancelled.
-
Approval flag: The contract must decide whether or not an event should be approved. Again, this will depend entirely on the use case, being the responsibility of the programmer to establish when it is necessary. Thus, approval is set as an optional but also conditional phase.
CAUTION
Kore contracts work without any associated status. All the information they can work with is what they receive as input. This means that the value of variables is not retained between executions, marking an important difference with respect to contracts on other platforms, such as Ethereum.Life cycle
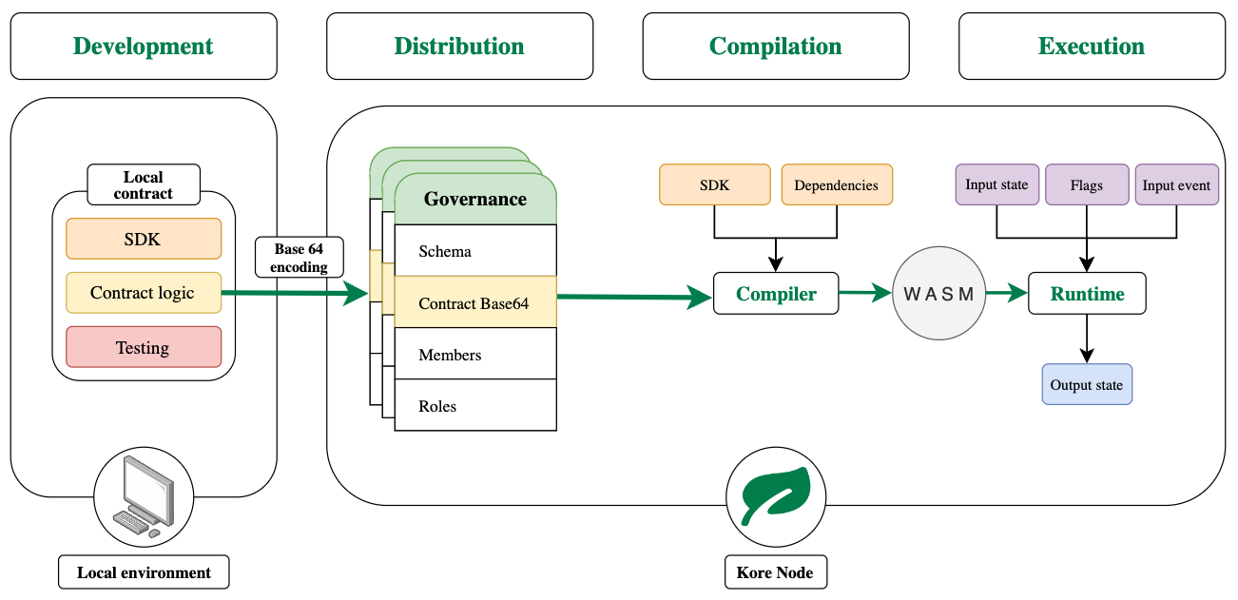
Development
Contracts are defined in local Rust projects, the only language allowed for writing them. These projects, which we must define as libraries, must import the SDK of the contracts available in the official repositories and, in addition, must follow the indications specified in “how to write a contract”.
Distribution
Once the contract has been defined, it must be included in a governance and associated to a schema so that it can be used by the nodes of a network. To this end, it is necessary to perform a governance update operation in which the contract is included in the corresponding section and coded in base64. If a test battery has been defined, it does not need to be included in the encoding process.
CAUTION
Since the Kore nodes are in charge of contract compilation, it is necessary that the base64 includes the contract in its entirety. In other words, the contract should be written entirely in a single file and encoded.
This is a current limitation and other alternatives are expected to be available in the future.
Compilation
If the update request is successful, the governance status will change and the evaluator nodes will compile the contract as a Web Assembly module, serialize it and store it in their database. This is an automated and self-managed process, so no user intervention is required at any stage of the process.
After this step, the contract can be used.
Execution
The execution of the contract will be done in a Web Assembly Runtime, isolating its execution from the rest of the system. This avoids the misuse of its resources, adding a layer of security.
Rust and WASM
Web Assembly is used for contract execution due to its characteristics:
- High performance and efficiency.
- It offers an isolated and secure execution environment.
- It has an active community.
- Allows compilation from several languages, many of them with a considerable user base.
- The modules resulting from the compilation, once optimized, are lightweight.
Rust was chosen as the language for writing Kore contracts because of its ability to compile to Web Assembly as well as its capabilities and specifications, the same reason that motivated its choice for the development of Kore. Specifically, Rust is a language focused on writing secure, high-performance code, both of which contribute to the quality of the resulting Web Assembly module. In addition, the language natively has the resources to create tests, which favors the testing of contracts.
2.2 - Programming contracts
SDK
For the correct development of the contracts it is necessary to use its SDK, a project that can be found in the official Kore repository. The main objective of this project is to abstract the programmer from the interaction with the context of the underlying evaluating machine, making it much easier to obtain the input data, as well as the process of writing the result of the contract.
The SDK project can be divided into three sections. On the one hand, a set of functions whose binding occurs at runtime and which are aimed at being able to interact with the evaluating machine, in particular, for reading and writing data to an internal buffer. Additionally, we also distinguish a module that, using the previous functions, is in charge of the serialization and deserialization of the data, as well as of providing the main function of any contract. Finally, we highlight a number of utility functions and structures that can be actively used in the code.
Many of the above elements are private, so the user will never have the opportunity to use them. Therefore, in this documentation we will focus on those that are exposed to the user and that the user will be able to actively use in the development of his contracts.
CAUTION
Please note that it is not possible to execute every function or use every type of data in a Web Assembly environment. You should inform yourself about the possibilities of the environment. For example, any interaction with the operating system is disabled, since it is an isolated and secure environment.Auxiliary structures
#[derive(Serialize, Deserialize, Debug)]
pub struct Context<State, Event> {
pub initial_state: State,
pub event: Event,
pub is_owner: bool,
}
This structure contains the three input data of any contract: the initial or current state of the subject, the incoming event and a flag indicating whether or not the person requesting the event is the owner of the subject. Note the use of generics for the state and the event.
#[derive(Serialize, Deserialize, Debug)]
pub struct ContractResult<State> {
pub final_state: State,
pub approval_required: bool,
pub success: bool,
}
It contains the result of the execution of the contract, being this a conjunction of the resulting state and two flags that indicate, on the one hand, if the execution has been successful according to the criteria established by the programmer (or if an error has occurred in the data loading); and on the other hand, if the event requires approval or not.
pub fn execute_contract<F, State, Event>(
state_ptr: i32,
event_ptr: i32,
is_owner: i32,
callback: F,
) -> u32
where
State: for<'a> Deserialize<'a> + Serialize + Clone,
Event: for<'a> Deserialize<'a> + Serialize,
F: Fn(&Context<State, Event>, &mut ContractResult<State>);
This function is the main function of the SDK and, likewise, the most important one. Specifically, it is in charge of obtaining the input data, data that it obtains from the context that it shares with the evaluating machine. The function, which will initially receive a pointer to each of these data, will be in charge of extracting them from the context and deserializing them to the state and event structures that the contract expects to receive, which can be specified by means of generics. These data, once obtained, are encapsulated in the Context structure present above and are passed as arguments to a callback function that manages the contract logic, i.e. it knows what to do with the data received. Finally, regardless of whether the execution has been successful or not, the function will take care of writing the result in the context, so that it can be used by the evaluating machine.
pub fn apply_patch<State: for<'a> Deserialize<'a> + Serialize>(
patch_arg: Value,
state: &State,
) -> Result<State, i32>;
This is the latest public feature of the SDK and allows to update a state by applying a JSON-PATCH, useful in cases where this technique is considered to update the state.
Your first contract
Creating the project
Locate the desired path and/or directories and create a new cargo package using cargo new NAME --lib. The project should be a library. Make sure you have a lib.rs file and not a main.rs file.
Then, include in the Cargo.toml as a dependency the SDK of the contracts and the rest of the dependencies you want from the following list:
- serde.
- serde_json.
- json_patch.
- thiserror.
The Cargo.toml should contain something like this:
[package]
name = "kore_contract"
version = "0.1.0"
edition = "2021"
[dependencies]
serde = { version = "=1.0.198", features = ["derive"] }
serde_json = "=1.0.116"
json-patch = "=1.2"
thiserror = "=1.0"
# Note: Change the tag label to the appropriate one
kore-contract-sdk = { git = "https://github.com/kore-ledger/kore-contract-sdk.git", branch = "main"}
Writing the contract
The following contract does not have a complicated logic since that aspect depends on the needs of the contract itself, but it does contain a wide range of the types that can be used and how they should be used. Since the compilation will be done by the node, we must write the whole contract in the lib.rs file.
In our case, we will start the contract by specifying the packages we are going to use.
use kore_contract_sdk as sdk;
use serde::{Deserialize, Serialize};
Next, it is necessary to specify the data structure that will represent the state of our subjects as well as the family of events that we will receive.
#[derive(Serialize, Deserialize, Clone)]
struct State {
pub text: String,
pub value: u32,
pub array: Vec<String>,
pub boolean: bool,
pub object: Object,
}
#[derive(Serialize, Deserialize, Clone)]
struct Object {
number: f32,
optional: Option<i32>,
}
#[derive(Serialize, Deserialize)]
enum StateEvent {
ChangeObject {
obj: Object,
},
ChangeOptional {
integer: i32,
},
ChangeAll {
text: String,
value: u32,
array: Vec<String>,
boolean: bool,
object: Object,
},
}
INFO
The event family will generally be defined as an enumerate, although in practice nothing prevents it from being a structure if required. Regardless of the case, if an enumerate is used, if its variants receive data, these must be specified by means of an anonymous structure and not by means of the tuple syntax.
It should also be noted that the events of the family can be subsets of the real events. Thus, as an example, the contract would accept a StateEvent::ChangeObject event that includes more data than the obj attribute. The contract, when executed, will only keep the necessary data, discarding all other data in the deserialization process. This could be used to store information in the string that is not needed for the contract logic.
CAUTION
Note that the implementation of the trait Serialize and Deserialize are mandatory to specify for state and events. Additionally, the former must also implement Clone.Next we define the contract entry function, the equivalent of the main function. It is important that this function always has the same name as the one specified here, since it is the identifier with which the evaluating machine will try to execute it, producing an error if it is not found.
#[no_mangle]
pub unsafe fn main_function(state_ptr: i32, event_ptr: i32, is_owner: i32) -> u32 {
sdk::execute_contract(state_ptr, event_ptr, is_owner, contract_logic)
}
This function must always be accompanied by the attribute #[no_mangle] and its input and output parameters must also match those of the example. Specifically, this function will receive the pointers to the input data, which will then be processed by the SDK function. As output, a new pointer to the result of the contract is generated, which, as mentioned above, is obtained by the SDK and not by the programmer.
INFO
Modifying the pointer values in this section of the code will have no effect. Pointers are with respect to the shared context, which corresponds to a single buffer per contract execution. Altering the pointer values does not allow the programmer to access arbitrary information either from the evaluating machine or from other contracts.Finally, we specify the logic of our contract, which can be defined by as many functions as we wish. Preferably a main function will be highlighted, which will be the one to be executed as callback by the execute_contract function of the SDK.
fn contract_logic(
context: &sdk::Context<State, StateEvent>,
contract_result: &mut sdk::ContractResult<State>,
) {
let state = &mut contract_result.final_state;
match &context.event {
StateEvent::ChangeObject { obj } => {
state.object = obj.to_owned();
}
StateEvent::ChangeOptional { integer } => state.object.optional = Some(*integer),
StateEvent::ChangeAll {
text,
value,
array,
boolean,
object,
} => {
state.text = text.to_string();
state.value = *value;
state.array = array.to_vec();
state.boolean = *boolean;
state.object = object.to_owned();
}
}
contract_result.success = true;
contract_result.approval_required = true;
}
This main function receives the contract input data encapsulated in an instance of the SDK Context structure. It also receives a mutable reference to the contract result containing the final state, originally identical to the initial state, and the approval required and successful execution flags, contract_result.approval_required and contract_result.success, respectively. Note how, in addition to modifying the status according to the event received, the previous flags must be modified. With the first flag we specify that the contract accepts the event and the changes it proposes for the current state of the subject, which will be translated in the SDK by generating a JSON_PATCH with the necessary modifications to move from the initial state to the obtained one. The second flag, on the other hand, allows us to conditionally indicate whether we consider that the event should be approved or not.
Testing your contract
Since this is Rust code, we can create a battery of unit tests in the contract code itself to check its performance using the resources of the language itself. It would also be possible to specify them in a different file.
// Testing Change Object
#[test]
fn contract_test_change_object() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeObject {
obj: Object {
number: 21.70,
optional: Some(64),
},
},
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(result.final_state.object.number, 21.70);
assert_eq!(result.final_state.object.optional, Some(64));
assert!(result.success);
assert!(result.approval_required);
}
// Testing Change Optional
#[test]
fn contract_test_change_optional() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
// Testing Change Object
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeOptional { integer: 1000 },
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(result.final_state.object.optional, Some(1000));
assert_eq!(result.final_state.object.number, 0.5);
assert!(result.success);
assert!(result.approval_required);
}
// Testing Change All
#[test]
fn contract_test_change_all() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
// Testing Change Object
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeAll {
text: "Kore_contract_test_all".to_string(),
value: 2024,
array: vec!["Kore".to_string(), "Ledger".to_string(), "SL".to_string()],
boolean: true,
object: Object {
number: 0.005,
optional: Some(2024),
},
},
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(
result.final_state.text,
"Kore_contract_test_all".to_string()
);
assert_eq!(result.final_state.value, 2024);
assert_eq!(
result.final_state.array,
vec!["Kore".to_string(), "Ledger".to_string(), "SL".to_string()]
);
assert_eq!(result.final_state.boolean, true);
assert_eq!(result.final_state.object.optional, Some(2024));
assert_eq!(result.final_state.object.number, 0.005);
assert!(result.success);
assert!(result.approval_required);
}
As you can see, the only thing you need to do to create a valid test is to manually define an initial state and an incoming event instead of using the SDK executor function, which can only be properly executed by Kore. Once the inputs are defined, making a call to the main function of the contract logic should be sufficient.
Once the contract is tested, it is ready to be sent to Kore as indicated in the introduction section. Note that it is not necessary to send the contract tests to the Kore nodes. In fact, sending them will result in a higher byte usage of the encoded file and, consequently, as it is stored in the governance, a higher byte consumption of the governance.
3 - Learn JSON Schema
JSON Schema specification
The JSON Schema specification is in DRAFT status in the IETF, however, it is widely used today and is practically considered a de facto standard.
JSON-Schema establishes a set of rules that model and validate a data structure. The following example defines a schema that models a simple data structure with 2 fields: id and value. It is also indicated that the id is mandatory and that no additional fields are allowed.
{
"type": "object",
"additionalProperties": false,
"required": [
"id"
],
"properties": {
"id": {"type":"string"},
"value": {"type":"integer"}
}
}
VALID JSON OBJECT
{
"id": "id_1",
"value": 23
}
INVALID JSON OBJECTS
{
"value": 3 // id is not defined and is mandatory
}
{
"id": "id_3",
"value": 3,
"count": 5 // additional properties are not allowed
}
JSON SCHEMA ONLINE VALIDATOR
You can test this behavior using this online and interactive JSON Schema validator.Creating a JSON-Schema
The following example is by no means definitive of all the value JSON Schema can provide. For this you will need to go deep into the specification itself. Learn more at json schema specification..
Let’s pretend we’re interacting with a JSON based car registration. This registration has a car which has:
- An manufacturer identifier:
chassisNumber - Identification of country of registration:
licensePlate - Number of kilometers driven:
mileage - An optional set of tags:
tags.
For example:
{
"chassisNumber": 72837362,
"licensePlate": "8256HYN",
"mileage": 60000,
"tags": [ "semi-new", "red" ]
}
While generally straightforward, the example leaves some open questions. Here are just a few of them:
- What is
chassisNumber? - Is
licensePlaterequired? - Can the
mileagebe less than zero? - Are all of the
tagsstring values?
When you’re talking about a data format, you want to have metadata about what keys mean, including the valid inputs for those keys. JSON Schema is a proposed IETF standard how to answer those questions for data.
Starting the schema
To start a schema definition, let’s begin with a basic JSON schema.
We start with four properties called keywords which are expressed as JSON keys.
Yes. the standard uses a JSON data document to describe data documents, most often that are also JSON data documents but could be in any number of other content types like
text/xml.
- The
$schemakeyword states that this schema is written according to a specific draft of the standard and used for a variety of reasons, primarily version control. - The
$idkeyword defines a URI for the schema, and the base URI that other URI references within the schema are resolved against. - The
titleanddescriptionannotation keywords are descriptive only. They do not add constraints to the data being validated. The intent of the schema is stated with these two keywords. - The
typevalidation keyword defines the first constraint on our JSON data and in this case it has to be a JSON Object.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object"
}
We introduce the following pieces of terminology when we start the schema:
- Schema Keyword:
$schemaand$id. - Schema Annotations:
titleanddescription. - Validation Keyword:
type.
Defining the properties
chassisNumber is a numeric value that uniquely identifies a car. Since this is the canonical identifier for a var, it doesn’t make sense to have a car without one, so it is required.
In JSON Schema terms, we update our schema to add:
- The
propertiesvalidation keyword. - The
chassisNumberkey.descriptionschema annotation andtypevalidation keyword is noted – we covered both of these in the previous section.
- The
requiredvalidation keyword listingchassisNumber.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
}
},
"required": [ "chassisNumber" ]
}
licensePlateis a string value that acting as a secondary identifier. Since there isn’t a car without a registration it also is required.- Since the
requiredvalidation keyword is an array of strings we can note multiple keys as required; We now includelicensePlate.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
}
},
"required": [ "chassisNumber", "licensePlate" ]
}
Going deeper with properties
According to the car registry, they cannot have negative mileage.
- The
mileagekey is added with the usualdescriptionschema annotation andtypevalidation keywords covered previously. It is also included in the array of keys defined by therequiredvalidation keyword. - We specify that the value of
mileagemust be greater than or equal to zero using theminimumvalidation keyword.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
Next, we come to the tags key.
The car registry has established the following:
- If there are tags there must be at least one tag,
- All tags must be unique; no duplication within a single car.
- All tags must be text.
- Tags are nice but they aren’t required to be present.
Therefore:
- The
tagskey is added with the usual annotations and keywords. - This time the
typevalidation keyword isarray. - We introduce the
itemsvalidation keyword so we can define what appears in the array. In this case:stringvalues via thetypevalidation keyword. - The
minItemsvalidation keyword is used to make sure there is at least one item in the array. - The
uniqueItemsvalidation keyword notes all of the items in the array must be unique relative to one another. - We did not add this key to the
requiredvalidation keyword array because it is optional.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
},
"tags": {
"description": "Tags for the car",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
Nesting data structures
Up until this point we’ve been dealing with a very flat schema – only one level. This section demonstrates nested data structures.
- The
dimensionskey is added using the concepts we’ve previously discovered. Since thetypevalidation keyword isobjectwe can use thepropertiesvalidation keyword to define a nested data structure.- We omitted the
descriptionannotation keyword for brevity in the example. While it’s usually preferable to annotate thoroughly in this case the structure and key names are fairly familiar to most developers.
- We omitted the
- You will note the scope of the
requiredvalidation keyword is applicable to the dimensions key and not beyond.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
},
"tags": {
"description": "Tags for the car",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
},
"dimensions": {
"type": "object",
"properties": {
"length": {
"type": "number"
},
"width": {
"type": "number"
},
"height": {
"type": "number"
}
},
"required": [ "length", "width", "height" ]
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
Taking a look at data for our defined JSON Schema
We’ve certainly expanded on the concept of a car since our earliest sample data (scroll up to the top). Let’s take a look at data which matches the JSON Schema we have defined.
{
"chassisNumber": 1,
"licensePlate": "8256HYN",
"mileage": 60000,
"tags": [ "semi-new", "red" ],
"dimensions": {
"length": 4.005,
"width": 1.932,
"height": 1.425
}
}
INFO
This tutorial is based on “Getting Started Step-By-Step” JSON-Schema tutorial. If you want to learn more about JSON-Schema, visit the JSON-Schema website for the original tutorial and other resources.4 - Kore Base
4.1 - Architecture
Kore Base is a library that implements most of the functionality of the Kore protocols. The most straightforward way to develop a Kore-compliant application is to use this library as, for example, Kore Client does.
Internally, it is structured in a series of layers with different responsibilities. The following is a simplified layer and block level view of the Kore Base structure.
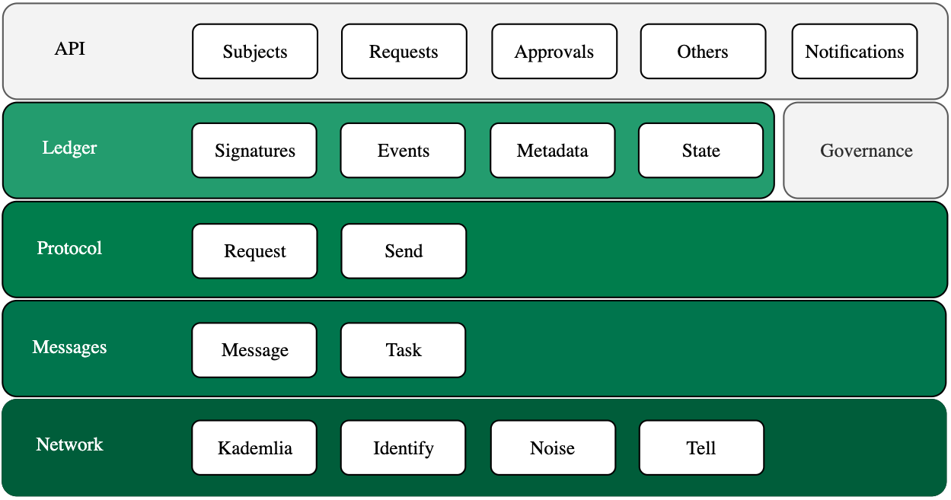
Network
Layer in charge of managing network communications, i.e., the sending and receiving of information between the different nodes of the network. Internally, the implementation is based on the use of LibP2P to resolve point-to-point communications. For this purpose, the following protocols are used:
- Kademlia, distributed hash table used as the foundation of peer routing functionality.
- Identify, protocol that allows peers to exchange information about each other, most notably their public keys and known network addresses.
- Noise, encryption scheme that allows for secure communication by combining cryptographic primitives into patterns with verifiable security properties.
- Tell, asynchronous protocol for sending messages. Tell arose within the development of Kore as an alternative to the LibP2P Request Response protocol that required waiting for responses.
Messages
Layer in charge of managing message sending tasks. The Kore communications protocol handles different types of messages. Some of them require a response. Since communications are asynchronous, we do not wait for an immediate response. This is why some types of messages have to be resent periodically until the necessary conditions are satisfied. This layer is responsible for encapsulating protocol messages and managing forwarding tasks.
Protocol
Layer in charge of managing the different types of messages of the Kore protocol and redirecting them to the parts of the application in charge of managing each type of message.
Ledger
Layer in charge of managing event chains, the micro-ledgers. This layer handles the management of subjects, events, status updates, updating of outdated chains, etc.
Governance
Module that manages the governances. Different parts of the application need to resolve conditions on the current or past state of some of the governance in which it participates. This module is in charge of managing these operations.
API
Layer in charge of exposing the functionality of the Kore node. Subject and event queries, request issuance or approval management are some of the functionalities exposed. A notification channel is also exposed in which different events occurring within the node are published, for example the creation of subjects or events.
4.2 - FFI
Kore has been designed with the intention that it can be built and run on different architectures, devices, and even from languages other than Rust.
Most of Kore’s functionality has been implemented in a library, Kore Base. However, this library alone does not allow running a Kore node since, for example, it needs a database implementation. This database must be provided by the software that integrates the Kore Base library. For example, Kore Client integrates a LevelDB database.
However, in order to run Kore on other architectures or languages we need a number of additional elements:
- Expose an Foreign Function Interface (FFI) that allows interacting with the Kore library from other languages.
- Target language bindings. Facilitating interaction with the library.
- Ability to cross-compile to the target architecture.
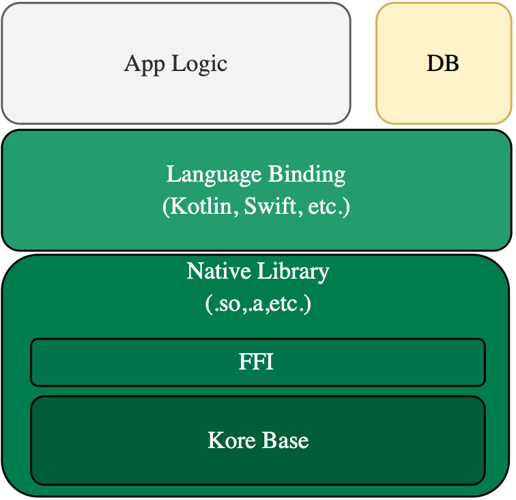
INFO
Explore the Kore repositories related to FFI for more information.5 - Kore Node
5.1 - What is
Kore Node is an intermediary between Kore Base and the different Kore Clients such as Kore HTTP. Its main functions are 4:
- Create an API that will be consumed by the different Kore Clients in order to communicate with Kore Base, the objective of this API is the simplification of the types, that is, it is responsible for receiving basic types such as
Stringand converting them into complex types that Kore Base expects to receive as aDigestIdentifier. Another objective of this API is to combine different methods of the Kore Base API to perform a specific functionality such as creating a traceability subject, in this way we add an abstraction layer on top of the Kore Base API. - Implement the different methods that the databases need so that Kore Base can use them, in this way Kore Base is not coupled with any database and by defining some methods it is capable of working with a LevelDB, a SQlite or a Cassandra.
- Receive configuration parameters through
.toml,.yamland.jsonfiles; in addition toenvironment variables. To delve deeper into the configuration parameters, visit the following section. - Optionally expose a Prometheus to obtain metrics. For more information on prometheus configuration visit the next section.
Currently Kore Node consists of 3 features:
- sqlite: To make use of the
SQlitedatabase. - leveldb: To make use of the
LevelDBdatabase. - prometheus: to expose an API with an
endpointcalled/metricswhere metrics can be obtained.
INFO
To access more information about how Kore Node works, access the repository5.2 - Configuration
These configuration parameters are general to any node regardless of the type of client to be used, the specific parameters of each client will be found in their respective sections.
Configuring a node can be done in different ways. The supported mechanisms are listed below, from lowest to highest priority:
- Environment Variables.
- Configuration file.
Environment Variables
The following configuration parameters can only be configured through environment variables and as parameters to the binary that is generated when the client is compiled, but not using files:
| Environment variable | Description | Input parameter | What you receive |
KORE_PASSWORD |
Password that will be used to encrypt the cryptographic material | -p |
The password |
KORE_FILE_PATH |
Path of the configuration file to use | -f |
File path |
The parameters that can be configured through environment variables and files are:
| Environment variable | Description | What you receive | Default value |
KORE_PROMETHEUS |
Address and port where the server that contains the endpoint /metrics where the prometheus is located is going to be exposed |
An IP address and a port | 0.0.0.0:3050 |
KORE_KEYS_PATH |
Path where the private key will be saved in PKCS8 format encrypted with PKCS5 |
A directory | examples/keys |
KORE_DB_PATH |
Path where the database will be created if it does not exist or where the database is located if it already exists | A directory | For LevelDB examples/leveldb and for SQlite examples/sqlitedb |
KORE_NODE_KEY_DERIVATOR |
Key derivator to use |
A String with Ed25519 or Secp256k1 |
Ed25519 |
KORE_NODE_DIGEST_DERIVATOR |
Digest derivator to use |
>A String with Blake3_256, Blake3_512, SHA2_256, SHA2_512, SHA3_256 or SHA3_512 |
Blake3_256 |
KORE_NODE_REPLICATION_FACTOR |
Percentage of network nodes that receive protocol messages in an iteration | Float value | 0.25 |
KORE_NODE_TIMEOUT |
Waiting time to be used between protocol iterations | Unsigned integer value | 3000 |
KORE_NODE_PASSVOTATION |
Node behavior in the approval phase | Unsigned integer value, 1 to always approve, 2 to always deny, another value for manual approval | 0 |
KORE_NODE_SMARTCONTRACTS_DIRECTORY |
Directory where the subjects' contracts will be stored | A directory | Contracts |
KORE_NETWORK_PORT_REUSE |
True to configure port reuse for local sockets, which involves reusing listening ports for outgoing connections to improve NAT traversal capabilities. | Boolean Value | false |
KORE_NETWORK_USER_AGENT |
The user agent | The user agent | kore-node |
KORE_NETWORK_NODE_TYPE |
Node type | A String: Bootstrap, Addressable or Ephemeral | Bootstrap |
KORE_NETWORK_LISTEN_ADDRESSES |
Addresses where the node will listen | Addresses where the node will listen | /ip4/0.0.0.0/tcp/50000 |
KORE_NETWORK_EXTERNAL_ADDRESSES |
External address through which the node can be accessed, but it is not among its interfaces | External address through which the node can be accessed, but it is not among its interfaces | /ip4/90.0.0.70/tcp/50000 |
KORE_NETWORK_ROUTING_BOOT_NODES |
Addresses of the Boot Nodes in the P2P network to which we will connect to become part of the network | Addresses of the Boot Nodes, where if it has more than one address it will be separated with a _ and the addresses are separated from the Peer-ID of the node using /p2p/ |
|
KORE_NETWORK_ROUTING_DHT_RANDOM_WALK |
True to enable random walk in Kademlia DHT |
Boolean Value | true |
KORE_NETWORK_ROUTING_DISCOVERY_ONLY_IF_UNDER_NUM |
Number of active connections for which we interrupt the discovery process | Number of active connections | u64::MAX |
KORE_NETWORK_ROUTING_ALLOW_NON_GLOBALS_IN_DHT |
True if non-global addresses are allowed in the DHT | Boolean Value | false |
KORE_NETWORK_ROUTING_ALLOW_PRIVATE_IP |
If the address of a node is false, it cannot be private | Boolean Value | false |
KORE_NETWORK_ROUTING_ENABLE_MDNS |
True to activate mDNS | Boolean Value | true |
KORE_NETWORK_ROUTING_KADEMLIA_DISJOINT_QUERY_PATHS |
When enabled, the number of separate paths used is equal to the configured parallelism | Boolean Value | true |
KORE_NETWORK_ROUTING_KADEMLIA_REPLICATION_FACTOR |
The replication factor determines how many closest peers a record is replicated to | Unsigned integer value greater than 0 | false |
KORE_NETWORK_ROUTING_PROTOCOL_NAMES |
Protocols supported by the node | Protocols supported by the node | /kore/routing/1.0.0 |
KORE_NETWORK_TELL_MESSAGE_TIMEOUT_SECS |
Message waiting time | Number of seconds | 10 |
KORE_NETWORK_TELL_MAX_CONCURRENT_STREAMS |
Maximum number of simultaneous transmissions | Unsigned integer value | 100 |
KORE_NETWORK_CONTROL_LIST_ENABLE |
Enable access control list | Boolean value | true |
KORE_NETWORK_CONTROL_LIST_ALLOW_LIST |
List of allowed peers | Comma separated text string | Peer200,Peer300 |
KORE_NETWORK_CONTROL_LIST_BLOCK_LIST |
List of blocked peers | Comma separated text string | Peer1,Peer2 |
KORE_NETWORK_CONTROL_LIST_SERVICE_ALLOW_LIST |
List of allowed service URLs | Comma separated text string | http://90.0.0.1:3000/allow_list |
KORE_NETWORK_CONTROL_LIST_SERVICE_BLOCK_LIST |
List of blocked service URLs | Comma separated text string | http://90.0.0.1:3000/block_list |
KORE_NETWORK_CONTROL_LIST_INTERVAL_REQUEST |
Request interval in seconds | Number of seconds | 58 |
.json File
{
"kore": {
"network": {
"user_agent": "Kore2.0",
"node_type": "Addressable",
"listen_addresses": ["/ip4/127.0.0.1/tcp/50000","/ip4/127.0.0.1/tcp/50001","/ip4/127.0.0.1/tcp/50002"],
"external_addresses": ["/ip4/90.1.0.60/tcp/50000", "/ip4/90.1.0.61/tcp/50000"],
"tell": {
"message_timeout_secs": 58,
"max_concurrent_streams": 166
},
"control_list": {
"enable": true,
"allow_list": ["Peer200", "Peer300"],
"block_list": ["Peer1", "Peer2"],
"service_allow_list": ["http://90.0.0.1:3000/allow_list", "http://90.0.0.2:4000/allow_list"],
"service_block_list": ["http://90.0.0.1:3000/block_list", "http://90.0.0.2:4000/block_list"],
"interval_request": 99
},
"routing": {
"boot_nodes": ["/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B","/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"],
"dht_random_walk": false,
"discovery_only_if_under_num": 55,
"allow_non_globals_in_dht": true,
"allow_private_ip": true,
"enable_mdns": false,
"kademlia_disjoint_query_paths": false,
"kademlia_replication_factor": 30,
"protocol_names": ["/kore/routing/2.2.2","/kore/routing/1.1.1"]
},
"port_reuse": true
},
"node": {
"key_derivator": "Secp256k1",
"digest_derivator": "Blake3_512",
"replication_factor": 0.555,
"timeout": 30,
"passvotation": 50,
"smartcontracts_directory": "./fake_route"
},
"db_path": "./fake/db/path",
"keys_path": "./fake/keys/path",
"prometheus": "10.0.0.0:3030"
}
}
.toml File
[kore.network]
user_agent = "Kore2.0"
node_type = "Addressable"
port_reuse = true
listen_addresses = ["/ip4/127.0.0.1/tcp/50000","/ip4/127.0.0.1/tcp/50001","/ip4/127.0.0.1/tcp/50002"]
external_addresses = ["/ip4/90.1.0.60/tcp/50000","/ip4/90.1.0.61/tcp/50000"]
[kore.network.control_list]
enable = true
allow_list = ["Peer200", "Peer300"]
block_list = ["Peer1", "Peer2"]
service_allow_list = ["http://90.0.0.1:3000/allow_list", "http://90.0.0.2:4000/allow_list"]
service_block_list = ["http://90.0.0.1:3000/block_list", "http://90.0.0.2:4000/block_list"]
interval_request = 99
[kore.network.tell]
message_timeout_secs = 58
max_concurrent_streams = 166
[kore.network.routing]
boot_nodes = ["/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B", "/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"]
dht_random_walk = false
discovery_only_if_under_num = 55
allow_non_globals_in_dht = true
allow_private_ip = true
enable_mdns = false
kademlia_disjoint_query_paths = false
kademlia_replication_factor = 30
protocol_names = ["/kore/routing/2.2.2", "/kore/routing/1.1.1"]
[kore.node]
key_derivator = "Secp256k1"
digest_derivator = "Blake3_512"
replication_factor = 0.555
timeout = 30
passvotation = 50
smartcontracts_directory = "./fake_route"
[kore]
db_path = "./fake/db/path"
keys_path = "./fake/keys/path"
prometheus = "10.0.0.0:3030"
.yaml File
kore:
network:
control_list:
allow_list:
- "Peer200"
- "Peer300"
block_list:
- "Peer1"
- "Peer2"
service_allow_list:
- "http://90.0.0.1:3000/allow_list"
- "http://90.0.0.2:4000/allow_list"
service_block_list:
- "http://90.0.0.1:3000/block_list"
- "http://90.0.0.2:4000/block_list"
interval_request: 99
enable: true
user_agent: "Kore2.0"
node_type: "Addressable"
listen_addresses:
- "/ip4/127.0.0.1/tcp/50000"
- "/ip4/127.0.0.1/tcp/50001"
- "/ip4/127.0.0.1/tcp/50002"
external_addresses:
- "/ip4/90.1.0.60/tcp/50000"
- "/ip4/90.1.0.61/tcp/50000"
tell:
message_timeout_secs: 58
max_concurrent_streams: 166
routing:
boot_nodes:
- "/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B"
- "/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"
dht_random_walk: false
discovery_only_if_under_num: 55
allow_non_globals_in_dht: true
allow_private_ip: true
enable_mdns: false
kademlia_disjoint_query_paths: false
kademlia_replication_factor: 30
protocol_names:
- "/kore/routing/2.2.2"
- "/kore/routing/1.1.1"
port_reuse: true
node:
key_derivator: "Secp256k1"
digest_derivator: "Blake3_512"
replication_factor: 0.555
timeout: 30
passvotation: 50
smartcontracts_directory: "./fake_route"
db_path: "./fake/db/path"
keys_path: "./fake/keys/path"
prometheus: "10.0.0.0:3030"
6 - Kore Clients
6.1 - Kore HTTP
It is a kore base client that uses the HTTP protocol, it allows to interact through an api with the Kore Ledger nodes. If you want to access information about the Api.
It has a single configuration variable that is only obtained by environment variable.
| Environment variable | Description | What you receive | Default values |
KORE_HTTP_ADDRESS |
Address where we can access the api | IP address and port | 0.0.0.0:3000 |
INFO
To access more information about how Kore HTTP works, access the repositoryfurthermore, once the node is deployed in the/doc path, it can be interacted with through the rapidoc interface.
6.2 - Kore Modbus
Coming soon
7 - Tools
Kore Tools are a group of utilities developed to facilitate the use of Kore Node, especially during testing and prototyping. In this section we will go deeper into them and how they can be obtained and used.
Installation
There are different ways in which the user can acquire these tools. The first and most basic is the generation of their binaries through the compilation of their source code, which can be obtained through the public repositories. However, we recommend making use of the available docker images in conjunction with a series of scripts that abstract the use of these images, so that the user does not need to compile the code.
Compiling binaries
$ git clone git@github.com:kore-ledger/kore-tools.git
$ cd kore-tools
$ sudo apt install -y libprotobuf-dev protobuf-compiler cmake
$ cargo install --locked --path keygen
$ cargo install --locked --path patch
$ cargo install --locked --path sign
$ kore-keygen -h
$ kore-sign -h
$ kore-patch -h
TIP
These utilities may be used relatively frequently, so we recommend that you include the scripts in the PATH to simplify their use.Kore Keygen
Any Kore node needs cryptographic material to function. To do so, it is necessary to generate it externally and then indicate it to the node, either by means of environment variables or through input parameters. The Kore Keygen utility satisfies this need by allowing, in a simple way, the generation of this cryptographic material. Specifically, its execution allows to obtain a private key in hexadecimal format, as well as the identifier (controller ID) which is the identifier at Kore level in which its format includes the public key, plus information of the cryptographic scheme used (you can obtain more information in the following link).
# Generate pkcs8 encrpty with pkcs5(ED25519)
kore-keygen -p a
kore-keygen -p a -r keys-Ed25519/private_key.der
kore-keygen -p a -r keys-Ed25519/public_key.der -d public-key
# Generate pkcs8 encrpty with pkcs5(SECP256K1)
kore-keygen -p a -m secp256k1
kore-keygen -p a -r keys-secp2561k/private_key.der -m secp256k1
kore-keygen -p a -r keys-secp2561k/public_key.der -m secp256k1 -d public-key
INFO
X and the other tools accept different execution arguments. For more information, try –help, for example:
Kore-keygen --help
Kore Sign
This is an utility that is intended to facilitate the execution of external invocations. In order to provide context, an external invocation is the process by which a node proposes a change to a network subject that it does not control, i.e., of which it is not the owner. There are also a number of rules that regulate which network users have the ability to perform these operations. In either case, the invoking node must present, in addition to the changes it wishes to suggest, a valid signature to prove its identity.
Kore Sign allows precisely the latter, generating the necessary signature to accompany the request for changes. Additionally, as the utility is strictly intended for such a scenario, what is actually returned by its execution is the entire data structure (in JSON format) that must be delivered to other nodes in the network for them to consider the request.
For the correct operation of the utility, it is necessary to pass as arguments both the event request data and the private key in hexadecimal format to be used.
# Basic usage example
kore-sign --id-private-key 2a71a0aff12c2de9e21d76e0538741aa9ac6da9ff7f467cf8b7211bd008a3198 '{"Transfer":{"subject_id":"JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU","public_key":"E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"}}'
// Output in json format
{
"request": {
"Transfer": {
"subject_id": "JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU",
"public_key": "E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"
}
},
"signature": {
"signer": "EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA",
"timestamp": 1717684953822643000,
"content_hash": "J1XWoQaLArB5q6B_PCfl4nzT36qqgoHzG-Uh32L_Q3cY",
"value": "SEYml_XhryHvxRylu023oyR0nIjlwVCyw2ZC_Tgvf04W8DnEzP9I3fFpHIc0eHrp46Exk8WIlG6fT1qp1bg1WgAg"
}
}
CAUTION
It is important to note that currently only private keys of the ED25519 algorithm are supportedTIP
If you need to pass the evento request to Kore-sign through a pipe instead of as an argument, you can use the xargs utility. For example,
echo '{"Transfer":{"subject_id":"JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU","public_key":"E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"}}' | xargs -0 -I {} kore-sign --id-private-key 2a71a0aff12c2de9e21d76e0538741aa9ac6da9ff7f467cf8b7211bd008a3198 {}
Kore Patch
Currently the contract that handles governance changes only allows one type of event that includes a JSON Patch.
JSON Patch is a data format that represents changes to JSON data structures. Thus, starting from an initial structure, after applying the JSON Patch, an updated structure is obtained. In the case of Kore, the JSON Patch defines the changes to be made to the data structure that represents governance when it needs to be modified. Kore Patch allows us to calculate the JSON Patch in a simple way if we have the original governance and the modified governance.
# Basic usage example
kore-patch '{"members":[]}' '{"members":[{"id":"EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA","name":"ACME"}]}'
// Output in json format
[
{
"op": "add",
"path": "/members/0",
"value": {
"id": "EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA",
"name": "ACME"
}
}
]
Once the JSON Patch is obtained it can be included in an event request to be sent to the governance owner.
TIP
Although Kore Patch has been developed to facilitate modifications to Kore governance, it is really just a utility that generates a JSON PATH from 2 JSON objects, so it can be used for other purposes.Control
Tool to provide a list of allowed and blocked nodes. It has 3 environment variables SERVERS that allows you to indicate how many servers you want and on which port you want them to listen and two lists ALLOWLIST and BLOCKLIST. These lists will be the default ones but you have a /allow and /block route with PUT and GET to modify them.
export SERVERS="0.0.0.0:3040,0.0.0.0:3041"
export ALLOWLIST="172.10.10.2"
control
Output
Server started at: 0.0.0.0:3040
Server started at: 0.0.0.0:3041